
搜索到
58
篇与
的结果
-
 K8s基于自定义指标实现自动扩容 基于自定义指标除了基于 CPU 和内存来进行自动扩缩容之外,我们还可以根据自定义的监控指标来进行。这个我们就需要使用 Prometheus Adapter,Prometheus 用于监控应用的负载和集群本身的各种指标,Prometheus Adapter 可以帮我们使用 Prometheus 收集的指标并使用它们来制定扩展策略,这些指标都是通过 APIServer 暴露的,而且 HPA 资源对象也可以很轻易的直接使用。下面来看具体怎么实现的!部署应用首先,我们部署一个示例应用,在该应用程序上测试 Prometheus 指标自动缩放,资源清单文件如下所示:(podinfo.yaml)--- apiVersion: apps/v1 kind: Deployment metadata: name: podinfo spec: selector: matchLabels: app: podinfo replicas: 1 template: metadata: labels: app: podinfo annotations: prometheus.io/scrape: 'true' spec: containers: - name: podinfod image: stefanprodan/podinfo:0.0.1 imagePullPolicy: Always command: - ./podinfo - -port=9898 - -logtostderr=true - -v=2 volumeMounts: - name: metadata mountPath: /etc/podinfod/metadata readOnly: true ports: - containerPort: 9898 protocol: TCP readinessProbe: httpGet: path: /readyz port: 9898 initialDelaySeconds: 1 periodSeconds: 2 failureThreshold: 1 livenessProbe: httpGet: path: /healthz port: 9898 initialDelaySeconds: 1 periodSeconds: 3 failureThreshold: 2 resources: requests: memory: "32Mi" cpu: "1m" limits: memory: "256Mi" cpu: "100m" volumes: - name: metadata downwardAPI: items: - path: "labels" fieldRef: fieldPath: metadata.labels - path: "annotations" fieldRef: fieldPath: metadata.annotations --- apiVersion: v1 kind: Service metadata: name: podinfo labels: app: podinfo spec: type: NodePort ports: - port: 9898 targetPort: 9898 nodePort: 31198 protocol: TCP selector: app: podinfo 接下来我们将 Prometheus-Adapter 安装到集群中,这里选用helm安装,当然也可以直接yaml文件安装。Prometheus-Adapter规则Prometheus-Adapter 规则大致 可以分为以下几个部分:seriesQuery:查询 Prometheus 的语句,通过这个查询语句查询到的所有指标都可以用于 HPA seriesFilters:查询到的指标可能会存在不需要的,可以通过它过滤掉。 resources:通过 seriesQuery 查询到的只是指标,如果需要查询某个 Pod 的指标,肯定要将它的名称和所在的命名空间作为指标的标签进行查询,resources 就是将指标的标签和 k8s 的资源类型关联起来,最常用的就是 pod 和 namespace。有两种添加标签的方式,一种是 overrides,另一种是 template。 overrides:它会将指标中的标签和 k8s 资源关联起来。上面示例中就是将指标中的 pod 和 namespace 标签和 k8s 中的 pod 和 namespace 关联起来,因为 pod 和 namespace 都属于核心 api 组,所以不需要指定 api 组。当我们查询某个 pod 的指标时,它会自动将 pod 的名称和名称空间作为标签加入到查询条件中。比如 pod: {group: "apps", resource: "deployment"} 这么写表示的就是将指标中 podinfo 这个标签和 apps 这个 api 组中的 deployment 资源关联起来; template:通过 go 模板的形式。比如template: "kube_<<.Group>>_<<.Resource>>" 这么写表示,假如 <<.Group>> 为 apps,<<.Resource>> 为 deployment,那么它就是将指标中 kube_apps_deployment 标签和 deployment 资源关联起来。 name:用来给指标重命名的,之所以要给指标重命名是因为有些指标是只增的,比如以 total 结尾的指标。这些指标拿来做 HPA 是没有意义的,我们一般计算它的速率,以速率作为值,那么此时的名称就不能以 total 结尾了,所以要进行重命名。 matches:通过正则表达式来匹配指标名,可以进行分组 as:默认值为 $1,也就是第一个分组。as 为空就是使用默认值的意思。 metricsQuery:这就是 Prometheus 的查询语句了,前面的 seriesQuery 查询是获得 HPA 指标。当我们要查某个指标的值时就要通过它指定的查询语句进行了。可以看到查询语句使用了速率和分组,这就是解决上面提到的只增指标的问题。 Series:表示指标名称 LabelMatchers:附加的标签,目前只有 pod 和 namespace 两种,因此我们要在之前使用 resources 进行关联 GroupBy:就是 pod 名称,同样需要使用 resources 进行关联。 安装我们新建 hpa-prome-adapter-values.yaml 文件覆盖默认的 Values 值 ,安装Prometheus-Adapter,我用的helm2文件如下:rules: default: false custom: - seriesQuery: 'http_requests_total' resources: overrides: kubernetes_namespace: resource: namespace kubernetes_pod_name: resource: pod name: matches: "^(.*)_total" as: "${1}_per_second" metricsQuery: (sum(rate(<<.Series>>{<<.LabelMatchers>>}[1m])) by (<<.GroupBy>>)) prometheus: url: http://prometheus-clusterip.monitor.svc.cluster.local 安装helm repo add apphub https://apphub.aliyuncs.com/ helm install --name prome-adapter --namespace monitor -f hpa-prome-adapter-values.yaml apphub/prometheus-adapter 等一小会儿,安装完成后,可以使用下面的命令来检测是否生效了:[root@prometheus]# kubectl get --raw="/apis/custom.metrics.k8s.io/v1beta1" | jq { "kind": "APIResourceList", "apiVersion": "v1", "groupVersion": "custom.metrics.k8s.io/v1beta1", "resources": [ { "name": "namespaces/http_requests_per_second", "singularName": "", "namespaced": false, "kind": "MetricValueList", "verbs": [ "get" ] }, { "name": "pods/http_requests_per_second", "singularName": "", "namespaced": true, "kind": "MetricValueList", "verbs": [ "get" ] } ] } 我们可以看到 http_requests_per_second 指标可用。 现在,让我们检查该指标的当前值:[root@prometheus]# kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/*/http_requests_per_second" | jq . { "kind": "MetricValueList", "apiVersion": "custom.metrics.k8s.io/v1beta1", "metadata": { "selfLink": "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/%2A/http_requests_per_second" }, "items": [ { "describedObject": { "kind": "Pod", "namespace": "default", "name": "podinfo-5cdc457c8b-99xtw", "apiVersion": "/v1" }, "metricName": "http_requests_per_second", "timestamp": "2020-06-02T12:01:01Z", "value": "888m", "selector": null }, { "describedObject": { "kind": "Pod", "namespace": "default", "name": "podinfo-5cdc457c8b-b7pfz", "apiVersion": "/v1" }, "metricName": "http_requests_per_second", "timestamp": "2020-06-02T12:01:01Z", "value": "888m", "selector": null } ] } 下面部署hpa对象apiVersion: autoscaling/v2beta1 kind: HorizontalPodAutoscaler metadata: name: podinfo spec: scaleTargetRef: apiVersion: extensions/v1beta1 kind: Deployment name: podinfo minReplicas: 2 maxReplicas: 5 metrics: - type: Pods pods: metricName: http_requests_per_second targetAverageValue: 3 部署之后,可见:[root@prometheus-adapter]# kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE podinfo Deployment/podinfo 911m/10 2 5 2 70s [root@prometheus-adapter]# kubectl describe hpa Name: podinfo Namespace: default Labels: <none> Annotations: kubectl.kubernetes.io/last-applied-configuration: {"apiVersion":"autoscaling/v2beta1","kind":"HorizontalPodAutoscaler","metadata":{"annotations":{},"name":"podinfo","namespace":"default"},... CreationTimestamp: Tue, 02 Jun 2020 17:53:14 +0800 Reference: Deployment/podinfo Metrics: ( current / target ) "http_requests_per_second" on pods: 911m / 10 Min replicas: 2 Max replicas: 5 Deployment pods: 2 current / 2 desired Conditions: Type Status Reason Message ---- ------ ------ ------- AbleToScale True ScaleDownStabilized recent recommendations were higher than current one, applying the highest recent recommendation ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from pods metric http_requests_per_second 做一个ab压测:ab -n 2000 -c 5 http://sy.test.com:31198/ 观察下hpa变化:Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulRescale 9m29s horizontal-pod-autoscaler New size: 3; reason: pods metric http_requests_per_second above target Normal SuccessfulRescale 9m18s horizontal-pod-autoscaler New size: 4; reason: pods metric http_requests_per_second above target Normal SuccessfulRescale 3m34s horizontal-pod-autoscaler New size: 3; reason: All metrics below target Normal SuccessfulRescale 3m4s horizontal-pod-autoscaler New size: 2; reason: All metrics below target 发现触发扩容动作了,副本到了4,并且压测结束后,过了5分钟左右,又恢复到最小值2个。参考链接:https://github.com/directxman12/k8s-prometheus-adapter院长技术
K8s基于自定义指标实现自动扩容 基于自定义指标除了基于 CPU 和内存来进行自动扩缩容之外,我们还可以根据自定义的监控指标来进行。这个我们就需要使用 Prometheus Adapter,Prometheus 用于监控应用的负载和集群本身的各种指标,Prometheus Adapter 可以帮我们使用 Prometheus 收集的指标并使用它们来制定扩展策略,这些指标都是通过 APIServer 暴露的,而且 HPA 资源对象也可以很轻易的直接使用。下面来看具体怎么实现的!部署应用首先,我们部署一个示例应用,在该应用程序上测试 Prometheus 指标自动缩放,资源清单文件如下所示:(podinfo.yaml)--- apiVersion: apps/v1 kind: Deployment metadata: name: podinfo spec: selector: matchLabels: app: podinfo replicas: 1 template: metadata: labels: app: podinfo annotations: prometheus.io/scrape: 'true' spec: containers: - name: podinfod image: stefanprodan/podinfo:0.0.1 imagePullPolicy: Always command: - ./podinfo - -port=9898 - -logtostderr=true - -v=2 volumeMounts: - name: metadata mountPath: /etc/podinfod/metadata readOnly: true ports: - containerPort: 9898 protocol: TCP readinessProbe: httpGet: path: /readyz port: 9898 initialDelaySeconds: 1 periodSeconds: 2 failureThreshold: 1 livenessProbe: httpGet: path: /healthz port: 9898 initialDelaySeconds: 1 periodSeconds: 3 failureThreshold: 2 resources: requests: memory: "32Mi" cpu: "1m" limits: memory: "256Mi" cpu: "100m" volumes: - name: metadata downwardAPI: items: - path: "labels" fieldRef: fieldPath: metadata.labels - path: "annotations" fieldRef: fieldPath: metadata.annotations --- apiVersion: v1 kind: Service metadata: name: podinfo labels: app: podinfo spec: type: NodePort ports: - port: 9898 targetPort: 9898 nodePort: 31198 protocol: TCP selector: app: podinfo 接下来我们将 Prometheus-Adapter 安装到集群中,这里选用helm安装,当然也可以直接yaml文件安装。Prometheus-Adapter规则Prometheus-Adapter 规则大致 可以分为以下几个部分:seriesQuery:查询 Prometheus 的语句,通过这个查询语句查询到的所有指标都可以用于 HPA seriesFilters:查询到的指标可能会存在不需要的,可以通过它过滤掉。 resources:通过 seriesQuery 查询到的只是指标,如果需要查询某个 Pod 的指标,肯定要将它的名称和所在的命名空间作为指标的标签进行查询,resources 就是将指标的标签和 k8s 的资源类型关联起来,最常用的就是 pod 和 namespace。有两种添加标签的方式,一种是 overrides,另一种是 template。 overrides:它会将指标中的标签和 k8s 资源关联起来。上面示例中就是将指标中的 pod 和 namespace 标签和 k8s 中的 pod 和 namespace 关联起来,因为 pod 和 namespace 都属于核心 api 组,所以不需要指定 api 组。当我们查询某个 pod 的指标时,它会自动将 pod 的名称和名称空间作为标签加入到查询条件中。比如 pod: {group: "apps", resource: "deployment"} 这么写表示的就是将指标中 podinfo 这个标签和 apps 这个 api 组中的 deployment 资源关联起来; template:通过 go 模板的形式。比如template: "kube_<<.Group>>_<<.Resource>>" 这么写表示,假如 <<.Group>> 为 apps,<<.Resource>> 为 deployment,那么它就是将指标中 kube_apps_deployment 标签和 deployment 资源关联起来。 name:用来给指标重命名的,之所以要给指标重命名是因为有些指标是只增的,比如以 total 结尾的指标。这些指标拿来做 HPA 是没有意义的,我们一般计算它的速率,以速率作为值,那么此时的名称就不能以 total 结尾了,所以要进行重命名。 matches:通过正则表达式来匹配指标名,可以进行分组 as:默认值为 $1,也就是第一个分组。as 为空就是使用默认值的意思。 metricsQuery:这就是 Prometheus 的查询语句了,前面的 seriesQuery 查询是获得 HPA 指标。当我们要查某个指标的值时就要通过它指定的查询语句进行了。可以看到查询语句使用了速率和分组,这就是解决上面提到的只增指标的问题。 Series:表示指标名称 LabelMatchers:附加的标签,目前只有 pod 和 namespace 两种,因此我们要在之前使用 resources 进行关联 GroupBy:就是 pod 名称,同样需要使用 resources 进行关联。 安装我们新建 hpa-prome-adapter-values.yaml 文件覆盖默认的 Values 值 ,安装Prometheus-Adapter,我用的helm2文件如下:rules: default: false custom: - seriesQuery: 'http_requests_total' resources: overrides: kubernetes_namespace: resource: namespace kubernetes_pod_name: resource: pod name: matches: "^(.*)_total" as: "${1}_per_second" metricsQuery: (sum(rate(<<.Series>>{<<.LabelMatchers>>}[1m])) by (<<.GroupBy>>)) prometheus: url: http://prometheus-clusterip.monitor.svc.cluster.local 安装helm repo add apphub https://apphub.aliyuncs.com/ helm install --name prome-adapter --namespace monitor -f hpa-prome-adapter-values.yaml apphub/prometheus-adapter 等一小会儿,安装完成后,可以使用下面的命令来检测是否生效了:[root@prometheus]# kubectl get --raw="/apis/custom.metrics.k8s.io/v1beta1" | jq { "kind": "APIResourceList", "apiVersion": "v1", "groupVersion": "custom.metrics.k8s.io/v1beta1", "resources": [ { "name": "namespaces/http_requests_per_second", "singularName": "", "namespaced": false, "kind": "MetricValueList", "verbs": [ "get" ] }, { "name": "pods/http_requests_per_second", "singularName": "", "namespaced": true, "kind": "MetricValueList", "verbs": [ "get" ] } ] } 我们可以看到 http_requests_per_second 指标可用。 现在,让我们检查该指标的当前值:[root@prometheus]# kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/*/http_requests_per_second" | jq . { "kind": "MetricValueList", "apiVersion": "custom.metrics.k8s.io/v1beta1", "metadata": { "selfLink": "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/%2A/http_requests_per_second" }, "items": [ { "describedObject": { "kind": "Pod", "namespace": "default", "name": "podinfo-5cdc457c8b-99xtw", "apiVersion": "/v1" }, "metricName": "http_requests_per_second", "timestamp": "2020-06-02T12:01:01Z", "value": "888m", "selector": null }, { "describedObject": { "kind": "Pod", "namespace": "default", "name": "podinfo-5cdc457c8b-b7pfz", "apiVersion": "/v1" }, "metricName": "http_requests_per_second", "timestamp": "2020-06-02T12:01:01Z", "value": "888m", "selector": null } ] } 下面部署hpa对象apiVersion: autoscaling/v2beta1 kind: HorizontalPodAutoscaler metadata: name: podinfo spec: scaleTargetRef: apiVersion: extensions/v1beta1 kind: Deployment name: podinfo minReplicas: 2 maxReplicas: 5 metrics: - type: Pods pods: metricName: http_requests_per_second targetAverageValue: 3 部署之后,可见:[root@prometheus-adapter]# kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE podinfo Deployment/podinfo 911m/10 2 5 2 70s [root@prometheus-adapter]# kubectl describe hpa Name: podinfo Namespace: default Labels: <none> Annotations: kubectl.kubernetes.io/last-applied-configuration: {"apiVersion":"autoscaling/v2beta1","kind":"HorizontalPodAutoscaler","metadata":{"annotations":{},"name":"podinfo","namespace":"default"},... CreationTimestamp: Tue, 02 Jun 2020 17:53:14 +0800 Reference: Deployment/podinfo Metrics: ( current / target ) "http_requests_per_second" on pods: 911m / 10 Min replicas: 2 Max replicas: 5 Deployment pods: 2 current / 2 desired Conditions: Type Status Reason Message ---- ------ ------ ------- AbleToScale True ScaleDownStabilized recent recommendations were higher than current one, applying the highest recent recommendation ScalingActive True ValidMetricFound the HPA was able to successfully calculate a replica count from pods metric http_requests_per_second 做一个ab压测:ab -n 2000 -c 5 http://sy.test.com:31198/ 观察下hpa变化:Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal SuccessfulRescale 9m29s horizontal-pod-autoscaler New size: 3; reason: pods metric http_requests_per_second above target Normal SuccessfulRescale 9m18s horizontal-pod-autoscaler New size: 4; reason: pods metric http_requests_per_second above target Normal SuccessfulRescale 3m34s horizontal-pod-autoscaler New size: 3; reason: All metrics below target Normal SuccessfulRescale 3m4s horizontal-pod-autoscaler New size: 2; reason: All metrics below target 发现触发扩容动作了,副本到了4,并且压测结束后,过了5分钟左右,又恢复到最小值2个。参考链接:https://github.com/directxman12/k8s-prometheus-adapter院长技术 -
-
iptables详解(5):iptables匹配条件总结之二(常用扩展模块) iptables详解(5):iptables匹配条件总结之二(常用扩展模块)本章 转载来自大佬朱双印引用地址 iptables在本博客中,从理论到实践,系统的介绍了iptables,如果你想要从头开始了解iptables,可以查看iptables文章列表,直达链接如下iptables零基础快速入门系列前文已经总结了iptables中的基本匹配条件,以及简单的扩展匹配条件,此处,我们来认识一些新的扩展模块。 iprange扩展模块之前我们已经总结过,在不使用任何扩展模块的情况下,使用-s选项或者-d选项即可匹配报文的源地址与目标地址,而且在指定IP地址时,可以同时指定多个IP地址,每个IP用”逗号”隔开,但是,-s选项与-d选项并不能一次性的指定一段连续的IP地址范围,如果我们需要指定一段连续的IP地址范围,可以使用iprange扩展模块。 使用iprange扩展模块可以指定”一段连续的IP地址范围”,用于匹配报文的源地址或者目标地址。iprange扩展模块中有两个扩展匹配条件可以使用–src-range–dst-range没错,见名知意,上述两个选项分别用于匹配报文的源地址所在范围与目标地址所在范围。 示例如下:上例表示如果报文的源IP地址如果在192.168.1.127到192.168.1.146之间,则丢弃报文,IP段的始末IP使用”横杠”连接,–src-range与–dst-range和其他匹配条件一样,能够使用”!”取反,有了前文中的知识作为基础,此处就不再赘述了。 string扩展模块使用string扩展模块,可以指定要匹配的字符串,如果报文中包含对应的字符串,则符合匹配条件。比如,如果报文中包含字符”OOXX”,我们就丢弃当前报文。首先,我们在IP为146的主机上启动http服务,然后在默认的页面目录中添加两个页面,页面中的内容分别为”OOXX”和”Hello World”,如下图所示,在没有配置任何规则时,126主机可以正常访问146主机上的这两个页面。那么,我们想要达到的目的是,如果报文中包含”OOXX”字符,我们就拒绝报文进入本机,所以,我们可以在126上进行如下配置。上图中,’-m string’表示使用string模块,’–algo bm’表示使用bm算法去匹配指定的字符串,’ –string “OOXX” ‘则表示我们想要匹配的字符串为”OOXX”设置完上图中的规则后,由于index.html中包含”OOXX”字符串,所以,146的回应报文无法通过126的INPUT链,所以无法获取到页面对应的内容。那么,我们来总结一下string模块的常用选项–algo:用于指定匹配算法,可选的算法有bm与kmp,此选项为必须选项,我们不用纠结于选择哪个算法,但是我们必须指定一个。–string:用于指定需要匹配的字符串。 time扩展模块我们可以通过time扩展模块,根据时间段区匹配报文,如果报文到达的时间在指定的时间范围以内,则符合匹配条件。比如,”我想要自我约束,每天早上9点到下午6点不能看网页”,擦,多么残忍的规定,如果你想要这样定义,可以尝试使用如下规则。上图中”-m time”表示使用time扩展模块,–timestart选项用于指定起始时间,–timestop选项用于指定结束时间。 如果你想要换一种约束方法,只有周六日不能看网页,那么可以使用如下规则。没错,如你所见,使用–weekdays选项可以指定每个星期的具体哪一天,可以同时指定多个,用逗号隔开,除了能够数字表示”星期几”,还能用缩写表示,例如:Mon, Tue, Wed, Thu, Fri, Sat, Sun 当然,你也可以将上述几个选项结合起来使用,比如指定只有周六日的早上9点到下午6点不能浏览网页。 聪明如你一定想到了,既然有–weekdays选项了,那么有没有–monthdays选项呢?必须有啊!使用–monthdays选项可以具体指定的每个月的哪一天,比如,如下图设置表示指明每月的22号,23号。 前文已经总结过,当一条规则中同时存在多个条件时,多个条件之间默认存在”与”的关系,所以,下图中的设置表示匹配的时间必须为星期5,并且这个”星期5″同时还需要是每个月的22号到28号之间的一天,所以,下图中的设置表示每个月的第4个星期5 除了使用–weekdays选项与–monthdays选项,还可以使用–datestart 选项与-datestop选项,指定具体的日期范围,如下。上图中指定的日期范围为2017年12月24日到2017年12月27日 上述选项中,–monthdays与–weekdays可以使用”!”取反,其他选项不能取反。 connlimit扩展模块使用connlimit扩展模块,可以限制每个IP地址同时链接到server端的链接数量,注意:我们不用指定IP,其默认就是针对”每个客户端IP”,即对单IP的并发连接数限制。比如,我们想要限制,每个IP地址最多只能占用两个ssh链接远程到server端,我们则可以进行如下限制。上例中,使用”-m connlimit”指定使用connlimit扩展,使用”–connlimit-above 2″表示限制每个IP的链接数量上限为2,再配合-p tcp –dport 22,即表示限制每个客户端IP的ssh并发链接数量不能高于2。centos6中,我们可以对–connlimit-above选项进行取反,没错,老规矩,使用”!”对此条件进行取反,示例如下上例表示,每个客户端IP的ssh链接数量只要不超过两个,则允许链接。但是聪明如你一定想到了,上例的规则并不能表示:每个客户端IP的ssh链接数量超过两个则拒绝链接(与前文中的举例原理相同,此处不再赘述,如果你不明白,请参考之前的文章)。也就是说,即使我们配置了上例中的规则,也不能达到”限制”的目的,所以我们通常并不会对此选项取反,因为既然使用了此选项,我们的目的通常就是”限制”连接数量。centos7中iptables为我们提供了一个新的选项,–connlimit-upto,这个选项的含义与”! –commlimit-above”的含义相同,即链接数量未达到指定的连接数量之意,所以综上所述,–connlimit-upto选项也不常用。 刚才说过,–connlimit-above默认表示限制”每个IP”的链接数量,其实,我们还可以配合–connlimit-mask选项,去限制”某类网段”的链接数量,示例如下:(注:下例需要一定的网络知识基础,如果你还不了解它们,可以选择先跳过此选项或者先去学习部分的网络知识)上例中,”–connlimit-mask 24″表示某个C类网段,没错,mask为掩码之意,所以将24转换成点分十进制就表示255.255.255.0,所以,上图示例的规则表示,一个最多包含254个IP的C类网络中,同时最多只能有2个ssh客户端连接到当前服务器,看来资源很紧俏啊!254个IP才有2个名额,如果一个IP同时把两个连接名额都占用了,那么剩下的253个IP连一个连接名额都没有了,那么,我们再看看下例,是不是就好多了。上例中,”–connlimit-mask 27″表示某个C类网段,通过计算后可以得知,这个网段中最多只能有30台机器(30个IP),这30个IP地址最多只能有10个ssh连接同时连接到服务器端,是不是比刚才的设置大方多了,当然,这样并不能避免某个IP占用所有连接的情况发生,假设,报文来自192.168.1.40这个IP,按照掩码为27进行计算,这个IP属于192.168.1.32/27网段,如果192.168.1.40同时占用了10个ssh连接,那么当192.168.1.51这个IP向服务端发起ssh连接请求时,同样会被拒绝,因为192.168.1.51这个IP按照掩码为27进行计算,也是属于192.168.1.32/27网段,所以他们共享这10个连接名额。 聪明如你一定明白了,在不使用–connlimit-mask的情况下,连接数量的限制是针对”每个IP”而言的,当使用了–connlimit-mask选项以后,则可以针对”某类IP段内的一定数量的IP”进行连接数量的限制,这样就能够灵活许多,不是吗? limit扩展模块刚才认识了connlimit模块,现在来认识一下limit模块。connlimit模块是对连接数量进行限制的,limit模块是对”报文到达速率”进行限制的。用大白话说就是,如果我想要限制单位时间内流入的包的数量,就能用limit模块。我们可以以秒为单位进行限制,也可以以分钟、小时、天作为单位进行限制。比如,限制每秒中最多流入3个包,或者限制每分钟最多流入30个包,都可以。那么,我们来看一个最简单的示例,假设,我们想要限制,外部主机对本机进行ping操作时,本机最多每6秒中放行一个ping包,那么,我们可以进行如下设置(注意,只进行如下设置有可能无法实现限制功能,请看完后面的内容)上例中,”-p icmp”表示我们针对ping请求添加了一条规则(ping使用icmp协议),”-m limit”表示使用limit模块, “–limit 10/minute -j ACCEPT”表示每分钟最多放行10个包,就相当于每6秒钟最多放行一个包,换句话说,就是每过6秒钟放行一个包,那么配置完上述规则后,我们在另外一台机器上对当前机器进行ping操作,看看是否能够达到限制的目的,如下图所示。我们发现,刚才配置的规则并没有如我们想象中的一样,ping请求的响应速率完全没有发生任何变化,为什么呢?我们一起来分析一下。我们再来回顾一下刚才配置的规则。其实,我们可以把上图中的规则理解为如下含义。每6秒放行一个包,那么iptables就会计时,每6秒一个轮次,到第6秒时,达到的报文就会匹配到对应的规则,执行对应的动作,而上图中的动作是ACCEPT。那么在第6秒之前到达的包,则无法被上述规则匹配到。之前总结过,报文会匹配链中的每一条规则,如果没有任何一条规则能够匹配到,则匹配默认动作(链的默认策略)。既然第6秒之前的包没有被上述规则匹配到,而我们又没有在INPUT链中配置其他规则,所以,第6秒之前的包肯定会被默认策略匹配到,那么我们看看默认策略是什么。现在再想想,我想你应该明白为什么刚才的ping的响应速率没有变化了。因为,上例中,第六秒的报文的确被对应的规则匹配到了,于是执行了”放行”操作,第6秒之前的报文没有被上图中配置的规则匹配到,但是被默认策略匹配到了,而恰巧,默认动作也是ACCEPT,所以,相当于所有的ping报文都被放行了,怪不得与没有配置规则时的速率一毛一样了。那么,知错就改,聪明如你一定想到了,我们可以修改INPUT链的默认策略,或者在上例限制规则的后面再加入一条规则,将”漏网之鱼”匹配到即可,示例如下。如上图所示,第一条规则表示每分钟最多放行10个icmp包,也就是6秒放行一个,第6秒的icmp包会被上例中的第一条规则匹配到,第6秒之前的包则不会被第一条规则匹配到,于是被后面的拒绝规则匹配到了,那么,此刻,我们再来试试,看看ping的报文放行速率有没有发生改变。如下图所示刚开始还真吓我一跳,难道配置的规则还是有问题?结果发现,只有前5个ping包没有受到限制,之后的ping包已经开始受到了规则的限制了。从上图可以看出,除了前5个ping包以外,之后的ping包差不多每6秒才能ping通一次,看来,之后的ping包已经受到了规则的控制,被限制了流入防火墙的速率了,那么,前5个ping包是什么鬼?为什么它们不受规则限制呢?其实,这个现象正好引出另一个话题,出现上图中的情况,是因为另一个选项:”–limit-burst”limit-burst选项是干什么用的呢?我们先用不准确的大白话描述一遍,”–limit-burst”可以指定”空闲时可放行的包的数量”,其实,这样说并不准确,但是我们可以先这样大概的理解,在不使用”–limit-burst”选项明确指定放行包的数量时,默认值为5,所以,才会出现上图中的情况,前5个ping包并没有受到任何速率限制,之后的包才受到了规则的限制。 如果想要彻底了解limit模块的工作原理,我们需要先了解一下”令牌桶”算法,因为limit模块使用了令牌桶算法。我们可以这样想象,有一个木桶,木桶里面放了5块令牌,而且这个木桶最多也只能放下5块令牌,所有报文如果想要出关入关,都必须要持有木桶中的令牌才行,这个木桶有一个神奇的功能,就是每隔6秒钟会生成一块新的令牌,如果此时,木桶中的令牌不足5块,那么新生成的令牌就存放在木桶中,如果木桶中已经存在5块令牌,新生成的令牌就无处安放了,只能溢出木桶(令牌被丢弃),如果此时有5个报文想要入关,那么这5个报文就去木桶里找令牌,正好一人一个,于是他们5个手持令牌,快乐的入关了,此时木桶空了,再有报文想要入关,已经没有对应的令牌可以使用了,但是,过了6秒钟,新的令牌生成了,此刻,正好来了一个报文想要入关,于是,这个报文拿起这个令牌,就入关了,在这个报文之后,如果很长一段时间内没有新的报文想要入关,木桶中的令牌又会慢慢的积攒了起来,直到达到5个令牌,并且一直保持着5个令牌,直到有人需要使用这些令牌,这就是令牌桶算法的大致逻辑。 那么,就拿刚才的”令牌桶”理论类比我们的命令,”–limit”选项就是用于指定”多长时间生成一个新令牌的”,”–limit-burst”选项就是用于指定”木桶中最多存放几个令牌的”,现在,你明白了吗??示例如下上例表示,令牌桶中最多能存放3个令牌,每分钟生成10个令牌(即6秒钟生成一个令牌)。之前说过,使用”–limit”选项时,可以选择的时间单位有多种,如下/second/minute/hour/day比如,3/second表示每秒生成3个”令牌”,30/minute表示每分钟生成30个”令牌”。我不知道我到底解释清楚没有,我感觉我解释清楚了,哥们儿你赶紧动手试试吧。 小结老规矩,为了方便以后回顾,我们将上文中提到的命令总结如下。 iprange模块包含的扩展匹配条件如下–src-range:指定连续的源地址范围–dst-range:指定连续的目标地址范围 #示例 iptables -t filter -I INPUT -m iprange --src-range 192.168.1.127-192.168.1.146 -j DROP iptables -t filter -I OUTPUT -m iprange --dst-range 192.168.1.127-192.168.1.146 -j DROP iptables -t filter -I INPUT -m iprange ! --src-range 192.168.1.127-192.168.1.146 -j DROP string模块常用扩展匹配条件如下–algo:指定对应的匹配算法,可用算法为bm、kmp,此选项为必需选项。–string:指定需要匹配的字符串 #示例 iptables -t filter -I INPUT -p tcp --sport 80 -m string --algo bm --string "OOXX" -j REJECT iptables -t filter -I INPUT -p tcp --sport 80 -m string --algo bm --string "OOXX" -j REJECT time模块常用扩展匹配条件如下–timestart:用于指定时间范围的开始时间,不可取反–timestop:用于指定时间范围的结束时间,不可取反–weekdays:用于指定”星期几”,可取反–monthdays:用于指定”几号”,可取反–datestart:用于指定日期范围的开始日期,不可取反–datestop:用于指定日期范围的结束时间,不可取反 #示例 iptables -t filter -I OUTPUT -p tcp --dport 80 -m time --timestart 09:00:00 --timestop 19:00:00 -j REJECT iptables -t filter -I OUTPUT -p tcp --dport 443 -m time --timestart 09:00:00 --timestop 19:00:00 -j REJECT iptables -t filter -I OUTPUT -p tcp --dport 80 -m time --weekdays 6,7 -j REJECT iptables -t filter -I OUTPUT -p tcp --dport 80 -m time --monthdays 22,23 -j REJECT iptables -t filter -I OUTPUT -p tcp --dport 80 -m time ! --monthdays 22,23 -j REJECT iptables -t filter -I OUTPUT -p tcp --dport 80 -m time --timestart 09:00:00 --timestop 18:00:00 --weekdays 6,7 -j REJECT iptables -t filter -I OUTPUT -p tcp --dport 80 -m time --weekdays 5 --monthdays 22,23,24,25,26,27,28 -j REJECT iptables -t filter -I OUTPUT -p tcp --dport 80 -m time --datestart 2017-12-24 --datestop 2017-12-27 -j REJECT connlimit 模块常用的扩展匹配条件如下–connlimit-above:单独使用此选项时,表示限制每个IP的链接数量。–connlimit-mask:此选项不能单独使用,在使用–connlimit-above选项时,配合此选项,则可以针对”某类IP段内的一定数量的IP”进行连接数量的限制,如果不明白可以参考上文的详细解释。 #示例 iptables -I INPUT -p tcp --dport 22 -m connlimit --connlimit-above 2 -j REJECT iptables -I INPUT -p tcp --dport 22 -m connlimit --connlimit-above 20 --connlimit-mask 24 -j REJECT iptables -I INPUT -p tcp --dport 22 -m connlimit --connlimit-above 10 --connlimit-mask 27 -j REJECT limit模块常用的扩展匹配条件如下–limit-burst:类比”令牌桶”算法,此选项用于指定令牌桶中令牌的最大数量,上文中已经详细的描述了”令牌桶”的概念,方便回顾。–limit:类比”令牌桶”算法,此选项用于指定令牌桶中生成新令牌的频率,可用时间单位有second、minute 、hour、day。 #示例 #注意,如下两条规则需配合使用,具体原因上文已经解释过,忘记了可以回顾。 iptables -t filter -I INPUT -p icmp -m limit --limit-burst 3 --limit 10/minute -j ACCEPT iptables -t filter -A INPUT -p icmp -j REJECT 希望这篇文章能够对你有所帮助~~~
-
YAML中多行字符串的配置方法 有时候我们会在配置文件中配置一段文字说明,这种时候通常会出现两种需求: 文字中可能出现段落,希望在配置中按段落方式编写,显示打印的时候也能出现段落换行。 文字很长,为方便编辑,可能在配置文件中分段写,但是显示的时候不喜欢出现配置中的段落换行。简单的说,就是: 配置与显示,都严格按段落展示 配置按段落,显示不需要按段落假设,我们需要配置这样一段文字: I am a coder.My blog is didispace.com. 下面,就针对上面的两种情况来看看可以怎么来实现:配置与显示,都严格按段落展示这个需求下,我们希望配置和显示都按句子换行,就是这样:I am a coder. My blog is didispace.com. 方法一:直接使用\n来换行这样写:string: "I am a coder.\n\ My blog is didispace.com." 最终输出:I am a coder. My blog is didispace.com. 通过\n在显示的时候换行,通过配置行末的\让这个字符串换行继续写(这个必须有,如果没有第二行行首会多一个空格)。注意:这里必须使用双引号来定义字符串,不能用单引号。因为单引号是不支持\n换行的。方法二:使用|、|+、|-在方法一种,其实我们在文字中加入了几个转义符号,其实对于阅读并不方便。在方法二中,将介绍更适合阅读的几种形式:string: | I am a coder. My blog is didispace.com. string: |+ I am a coder. My blog is didispace.com. string: |- I am a coder. My blog is didispace.com. 如上面一共有三种配置都会自动按配置中所写的换行来换行,但是在文末会有一些区别,有的会增加一个空行,有的不会,有的会新增两个空行,具体说明如下: |:文中自动换行 + 文末新增一空行 |+:文中自动换行 + 文末新增两空行 |-:文中自动换行 + 文末不新增行 配置按段落,显示不需要按段落这个需求下,我们希望配置里是按行写的,但是显示是如下面这样在一行的:I am a coder.My blog is didispace.com. 方法一:直接在字符串中换行写最粗暴的写法,反正不用换行,那就直接写了:string: 'I am a coder. My blog is didispace.com.' 这里不论用双引号还是单引号都是可以的。因为不存在需要转移的内容,所以总体还算清晰。方法二:使用>、>+、>-比较好的表述方式就是使用>、>+、>-来定义,比如下面这几种:string: > I am a coder. My blog is didispace.com. string: >+ I am a coder. My blog is didispace.com. string: >- I am a coder. My blog is didispace.com. 这三种都不会对配置中的换行进行实际换行,但是依然在文末的处理会有一些小区别,具体如下: >:文中不自动换行 + 文末新增一空行 >+:文中不自动换行 + 文末新增两空行 >-:文中不自动换行 + 文末不新增行
-
什么是Nginx Nginx是一个 轻量级/高性能的反向代理Web服务器,用于 HTTP、HTTPS、SMTP、POP3 和 IMAP 协议。他实现非常高效的反向代理、负载平衡,他可以处理2-3万并发连接数,官方监测能支持5万并发,现在中国使用nginx网站用户有很多,例如:新浪、网易、 腾讯等。Nginx 有哪些优点? 跨平台、配置简单。 非阻塞、高并发连接:处理 2-3 万并发连接数,官方监测能支持 5 万并发。 内存消耗小:开启 10 个 Nginx 才占 150M 内存。 成本低廉,且开源。 稳定性高,宕机的概率非常小。 内置的健康检查功能:如果有一个服务器宕机,会做一个健康检查,再发送的请求就不会发送到宕机的服务器了。重新将请求提交到其他的节点上 Nginx应用场景? http服务器。Nginx是一个http服务可以独立提供http服务。可以做网页静态服务器。 虚拟主机。可以实现在一台服务器虚拟出多个网站,例如个人网站使用的虚拟机。 反向代理,负载均衡。当网站的访问量达到一定程度后,单台服务器不能满足用户的请求时,需要用多台服务器集群可以使用nginx做反向代理。并且多台服务器可以平均分担负载,不会应为某台服务器负载高宕机而某台服务器闲置的情况。 nginz 中也可以配置安全管理、比如可以使用Nginx搭建API接口网关,对每个接口服务进行拦截。 Nginx怎么处理请求的?server { # 第一个Server区块开始,表示一个独立的虚拟主机站点 listen 80; # 提供服务的端口,默认80 server_name localhost; # 提供服务的域名主机名 location / { # 第一个location区块开始 root html; # 站点的根目录,相当于Nginx的安装目录 index index.html index.html; # 默认的首页文件,多个用空格分开 } 首先,Nginx 在启动时,会解析配置文件,得到需要监听的端口与 IP 地址,然后在 Nginx 的 Master 进程里面先初始化好这个监控的Socket(创建 S ocket,设置 addr、reuse 等选项,绑定到指定的 ip 地址端口,再 listen 监听)。 然后,再 fork(一个现有进程可以调用 fork 函数创建一个新进程。由 fork 创建的新进程被称为子进程 )出多个子进程出来。 之后,子进程会竞争 accept 新的连接。此时,客户端就可以向 nginx 发起连接了。当客户端与nginx进行三次握手,与 nginx 建立好一个连接后。此时,某一个子进程会 accept 成功,得到这个建立好的连接的 Socket ,然后创建 nginx 对连接的封装,即 ngx_connection_t 结构体。 接着,设置读写事件处理函数,并添加读写事件来与客户端进行数据的交换。 最后,Nginx 或客户端来主动关掉连接,到此,一个连接就寿终正寝了。 Nginx 是如何实现高并发的?如果一个 server 采用一个进程(或者线程)负责一个request的方式,那么进程数就是并发数。那么显而易见的,就是会有很多进程在等待中。等什么?最多的应该是等待网络传输。而 Nginx 的异步非阻塞工作方式正是利用了这点等待的时间。在需要等待的时候,这些进程就空闲出来待命了。因此表现为少数几个进程就解决了大量的并发问题。Nginx是如何利用的呢,简单来说:同样的 4 个进程,如果采用一个进程负责一个 request 的方式,那么,同时进来 4 个 request 之后,每个进程就负责其中一个,直至会话关闭。期间,如果有第 5 个request进来了。就无法及时反应了,因为 4 个进程都没干完活呢,因此,一般有个调度进程,每当新进来了一个 request ,就新开个进程来处理。回想下,BIO 是不是存在酱紫的问题?Nginx 不这样,每进来一个 request ,会有一个 worker 进程去处理。但不是全程的处理,处理到什么程度呢?处理到可能发生阻塞的地方,比如向上游(后端)服务器转发 request ,并等待请求返回。那么,这个处理的 worker 不会这么傻等着,他会在发送完请求后,注册一个事件:如果 upstream 返回了,告诉我一声,我再接着干。于是他就休息去了。此时,如果再有 request 进来,他就可以很快再按这种方式处理。而一旦上游服务器返回了,就会触发这个事件,worker 才会来接手,这个 request 才会接着往下走。这就是为什么说,Nginx 基于事件模型。由于 web server 的工作性质决定了每个 request 的大部份生命都是在网络传输中,实际上花费在 server 机器上的时间片不多。这是几个进程就解决高并发的秘密所在。即:webserver 刚好属于网络 IO 密集型应用,不算是计算密集型。异步,非阻塞,使用 epoll ,和大量细节处的优化。也正是 Nginx 之所以然的技术基石。什么是正向代理?一个位于客户端和原始服务器(origin server)之间的服务器,为了从原始服务器取得内容,客户端向代理发送一个请求并指定目标(原始服务器),然后代理向原始服务器转交请求并将获得的内容返回给客户端。客户端才能使用正向代理。正向代理总结就一句话:代理端代理的是客户端。例如说:我们使用的OpenVPN 等等。什么是反向代理?反向代理(Reverse Proxy)方式,是指以代理服务器来接受 Internet上的连接请求,然后将请求,发给内部网络上的服务器并将从服务器上得到的结果返回给 Internet 上请求连接的客户端,此时代理服务器对外就表现为一个反向代理服务器。反向代理总结就一句话:代理端代理的是服务端。“反向代理服务器的优点是什么?反向代理服务器可以隐藏源服务器的存在和特征。它充当互联网云和web服务器之间的中间层。这对于安全方面来说是很好的,特别是当您使用web托管服务时。Nginx目录结构有哪些?[root@localhost ~]# tree /usr/local/nginx /usr/local/nginx ├── client_body_temp ├── conf # Nginx所有配置文件的目录 │ ├── fastcgi.conf # fastcgi相关参数的配置文件 │ ├── fastcgi.conf.default # fastcgi.conf的原始备份文件 │ ├── fastcgi_params # fastcgi的参数文件 │ ├── fastcgi_params.default │ ├── koi-utf │ ├── koi-win │ ├── mime.types # 媒体类型 │ ├── mime.types.default │ ├── nginx.conf # Nginx主配置文件 │ ├── nginx.conf.default │ ├── scgi_params # scgi相关参数文件 │ ├── scgi_params.default │ ├── uwsgi_params # uwsgi相关参数文件 │ ├── uwsgi_params.default │ └── win-utf ├── fastcgi_temp # fastcgi临时数据目录 ├── html # Nginx默认站点目录 │ ├── 50x.html # 错误页面优雅替代显示文件,例如当出现502错误时会调用此页面 │ └── index.html # 默认的首页文件 ├── logs # Nginx日志目录 │ ├── access.log # 访问日志文件 │ ├── error.log # 错误日志文件 │ └── nginx.pid # pid文件,Nginx进程启动后,会把所有进程的ID号写到此文件 ├── proxy_temp # 临时目录 ├── sbin # Nginx命令目录 │ └── nginx # Nginx的启动命令 ├── scgi_temp # 临时目录 └── uwsgi_temp # 临时目录 Nginx配置文件nginx.conf有哪些属性模块?worker_processes 1; # worker进程的数量 events { # 事件区块开始 worker_connections 1024; # 每个worker进程支持的最大连接数 } # 事件区块结束 http { # HTTP区块开始 include mime.types; # Nginx支持的媒体类型库文件 default_type application/octet-stream; # 默认的媒体类型 sendfile on; # 开启高效传输模式 keepalive_timeout 65; # 连接超时 server { # 第一个Server区块开始,表示一个独立的虚拟主机站点 listen 80; # 提供服务的端口,默认80 server_name localhost; # 提供服务的域名主机名 location / { # 第一个location区块开始 root html; # 站点的根目录,相当于Nginx的安装目录 index index.html index.htm; # 默认的首页文件,多个用空格分开 } # 第一个location区块结果 error_page 500502503504 /50x.html; # 出现对应的http状态码时,使用50x.html回应客户 location = /50x.html { # location区块开始,访问50x.html root html; # 指定对应的站点目录为html } } ...... cookie和session区别? 共同: 存放用户信息。存放的形式:key-value格式 变量和变量内容键值对。 区别: cookie 存放在客户端浏览器 每个域名对应一个cookie,不能跨跃域名访问其他cookie 用户可以查看或修改cookie http响应报文里面给你浏览器设置 钥匙(用于打开浏览器上锁头) session: 存放在服务器(文件,数据库,redis) 存放敏感信息 锁头 为什么 Nginx 不使用多线程?Apache: 创建多个进程或线程,而每个进程或线程都会为其分配 cpu 和内存(线程要比进程小的多,所以 worker 支持比 perfork 高的并发),并发过大会榨干服务器资源。Nginx: 采用单线程来异步非阻塞处理请求(管理员可以配置 Nginx 主进程的工作进程的数量)(epoll),不会为每个请求分配 cpu 和内存资源,节省了大量资源,同时也减少了大量的 CPU 的上下文切换。所以才使得 Nginx 支持更高的并发。nginx和apache的区别轻量级,同样起web服务,比apache占用更少的内存和资源。抗并发,nginx处理请求是异步非阻塞的,而apache则是阻塞性的,在高并发下nginx能保持低资源,低消耗高性能。高度模块化的设计,编写模块相对简单。最核心的区别在于apache是同步多进程模型,一个连接对应一个进程,nginx是异步的,多个连接可以对应一个进程。什么是动态资源、静态资源分离?动态资源、静态资源分离,是让动态网站里的动态网页根据一定规则把不变的资源和经常变的资源区分开来,动静资源做好了拆分以后我们就可以根据静态资源的特点将其做缓存操作,这就是网站静态化处理的核心思路。动态资源、静态资源分离简单的概括是:动态文件与静态文件的分离。为什么要做动、静分离?在我们的软件开发中,有些请求是需要后台处理的(如:.jsp,.do 等等),有些请求是不需要经过后台处理的(如:css、html、jpg、js 等等文件),这些不需要经过后台处理的文件称为静态文件,否则动态文件。因此我们后台处理忽略静态文件。这会有人又说那我后台忽略静态文件不就完了吗?当然这是可以的,但是这样后台的请求次数就明显增多了。在我们对资源的响应速度有要求的时候,我们应该使用这种动静分离的策略去解决动、静分离将网站静态资源(HTML,JavaScript,CSS,img等文件)与后台应用分开部署,提高用户访问静态代码的速度,降低对后台应用访问这里我们将静态资源放到 Nginx 中,动态资源转发到 Tomcat 服务器中去。当然,因为现在七牛、阿里云等 CDN 服务已经很成熟,主流的做法,是把静态资源缓存到 CDN 服务中,从而提升访问速度。相比本地的 Nginx 来说,CDN 服务器由于在国内有更多的节点,可以实现用户的就近访问。并且,CDN 服务可以提供更大的带宽,不像我们自己的应用服务,提供的带宽是有限的。什么叫 CDN 服务?CDN ,即内容分发网络。其目的是,通过在现有的 Internet中 增加一层新的网络架构,将网站的内容发布到最接近用户的网络边缘,使用户可就近取得所需的内容,提高用户访问网站的速度。一般来说,因为现在 CDN 服务比较大众,所以基本所有公司都会使用 CDN 服务。Nginx怎么做的动静分离?只需要指定路径对应的目录。location/可以使用正则表达式匹配。并指定对应的硬盘中的目录。如下:(操作都是在Linux上)location /image/ { root /usr/local/static/; autoindex on; } 步骤:# 创建目录 mkdir /usr/local/static/image # 进入目录 cd /usr/local/static/image # 上传照片 photo.jpg # 重启nginx sudo nginx -s reload 打开浏览器 输入 server_name/image/1.jpg 就可以访问该静态图片了Nginx负载均衡的算法怎么实现的?策略有哪些?为了避免服务器崩溃,大家会通过负载均衡的方式来分担服务器压力。将对台服务器组成一个集群,当用户访问时,先访问到一个转发服务器,再由转发服务器将访问分发到压力更小的服务器。Nginx负载均衡实现的策略有以下五种: 1 .轮询(默认) 每个请求按时间顺序逐一分配到不同的后端服务器,如果后端某个服务器宕机,能自动剔除故障系统。 upstream backserver { server 1112; server 1113; } 2.权重 weight的值越大,分配到的访问概率越高,主要用于后端每台服务器性能不均衡的情况下。其次是为在主从的情况下设置不同的权值,达到合理有效的地利用主机资源。 # 权重越高,在被访问的概率越大,如上例,分别是20%,80%。 upstream backserver { server 1112 weight=2; server 1113 weight=8; } 3.ip_hash( IP绑定) 每个请求按访问IP的哈希结果分配,使来自同一个IP的访客固定访问一台后端服务器,并且可以有效解决动态网页存在的session共享问题 upstream backserver { ip_hash; server 1112:88; server 1113:80; } fair(第三方插件)必须安装upstream_fair模块。 对比 weight、ip_hash更加智能的负载均衡算法,fair算法可以根据页面大小和加载时间长短智能地进行负载均衡,响应时间短的优先分配。# 哪个服务器的响应速度快,就将请求分配到那个服务器上。 upstream backserver { server server1; server server2; fair; } 5.url_hash(第三方插件)必须安装Nginx的hash软件包 按访问url的hash结果来分配请求,使每个url定向到同一个后端服务器,可以进一步提高后端缓存服务器的效率。upstream backserver { server squid1:3128; server squid2:3128; hash $request_uri; hash_method crc32; } 如何用Nginx解决前端跨域问题?使用Nginx转发请求。把跨域的接口写成调本域的接口,然后将这些接口转发到真正的请求地址。Nginx虚拟主机怎么配置?`1、基于域名的虚拟主机,通过域名来区分虚拟主机——应用:外部网站2、基于端口的虚拟主机,通过端口来区分虚拟主机——应用:公司内部网站,外部网站的管理后台3、基于ip的虚拟主机。基于虚拟主机配置域名需要建立/data/www /data/bbs目录,windows本地hosts添加虚拟机ip地址对应的域名解析;对应域名网站目录下新增index.html文件; # 当客户端访问www.lijie.com,监听端口号为80,直接跳转到data/www目录下文件 server { listen 80; server_name www.lijie.com; location / { root data/www; index index.html index.htm; } } # 当客户端访问www.lijie.com,监听端口号为80,直接跳转到data/bbs目录下文件 server { listen 80; server_name bbs.lijie.com; location / { root data/bbs; index index.html index.htm; } } 基于端口的虚拟主机使用端口来区分,浏览器使用域名或ip地址:端口号 访问# 当客户端访问www.lijie.com,监听端口号为8080,直接跳转到data/www目录下文件 server { listen 8080; server_name 8080.lijie.com; location / { root data/www; index index.html index.htm; } } # 当客户端访问www.lijie.com,监听端口号为80直接跳转到真实ip服务器地址 127.0.0.1:8080 server { listen 80; server_name www.lijie.com; location / { proxy_pass http://127.0.0.1:8080; index index.html index.htm; } } location的作用是什么?location指令的作用是根据用户请求的URI来执行不同的应用,也就是根据用户请求的网站URL进行匹配,匹配成功即进行相关的操作。location的语法能说出来吗?注意:~ 代表自己输入的英文字母Location正则案例# 优先级1,精确匹配,根路径 location =/ { return 400; } # 优先级2,以某个字符串开头,以av开头的,优先匹配这里,区分大小写 location ^~ /av { root /data/av/; } # 优先级3,区分大小写的正则匹配,匹配/media*****路径 location ~ /media { alias /data/static/; } # 优先级4 ,不区分大小写的正则匹配,所有的****.jpg|gif|png 都走这里 location ~* .*\.(jpg|gif|png|js|css)$ { root /data/av/; } # 优先7,通用匹配 location / { return 403; } 限流怎么做的?Nginx限流就是限制用户请求速度,防止服务器受不了限流有3种 正常限制访问频率(正常流量) 突发限制访问频率(突发流量) 限制并发连接数Nginx的限流都是基于漏桶流算法 实现三种限流算法 1、正常限制访问频率(正常流量):限制一个用户发送的请求,我Nginx多久接收一个请求。 Nginx中使用ngx_http_limit_req_module模块来限制的访问频率,限制的原理实质是基于漏桶算法原理来实现的。在nginx.conf配置文件中可以使用limit_req_zone命令及limit_req命令限制单个IP的请求处理频率。# 定义限流维度,一个用户一分钟一个请求进来,多余的全部漏掉 limit_req_zone $binary_remote_addr zone=one:10m rate=1r/m; # 绑定限流维度 server{ location /seckill.html{ limit_req zone=zone; proxy_pass http://lj_seckill; } } 1r/s代表1秒一个请求,1r/m一分钟接收一个请求, 如果Nginx这时还有别人的请求没有处理完,Nginx就会拒绝处理该用户请求。 2、突发限制访问频率(突发流量):限制一个用户发送的请求,我Nginx多久接收一个。 上面的配置一定程度可以限制访问频率,但是也存在着一个问题:如果突发流量超出请求被拒绝处理,无法处理活动时候的突发流量,这时候应该如何进一步处理呢?Nginx提供burst参数结合nodelay参数可以解决流量突发的问题,可以设置能处理的超过设置的请求数外能额外处理的请求数。我们可以将之前的例子添加burst参数以及nodelay参数:# 定义限流维度,一个用户一分钟一个请求进来,多余的全部漏掉 limit_req_zone $binary_remote_addr zone=one:10m rate=1r/m; # 绑定限流维度 server{ location/seckill.html{ limit_req zone=zone burst=5 nodelay; proxy_pass http://lj_seckill; } } 为什么就多了一个 burst=5 nodelay; 呢,多了这个可以代表Nginx对于一个用户的请求会立即处理前五个,多余的就慢慢来落,没有其他用户的请求我就处理你的,有其他的请求的话我Nginx就漏掉不接受你的请求 3、 限制并发连接数Nginx中的 ngx_http_limit_conn_module模块提供了限制并发连接数的功能,可以使用limit_conn_zone指令以及limit_conn执行进行配置。接下来我们可以通过一个简单的例子来看下:http { limit_conn_zone $binary_remote_addr zone=myip:10m; limit_conn_zone $server_name zone=myServerName:10m; } server { location / { limit_conn myip 10; limit_conn myServerName 100; rewrite / http://www.rumenz.net permanent; } } 上面配置了单个IP同时并发连接数最多只能10个连接,并且设置了整个虚拟服务器同时最大并发数最多只能100个链接。当然,只有当请求的header被服务器处理后,虚拟服务器的连接数才会计数。刚才有提到过Nginx是基于漏桶算法原理实现的,实际上限流一般都是基于漏桶算法和令牌桶算法实现的。漏桶流算法和令牌桶算法知道?一文搞定,手撸Springboot + aop + Lua分布式限流的最佳实践_vincent-CSDN博客_springboot如何限流漏桶算法:漏桶算法思路很简单,我们把水比作是请求,漏桶比作是系统处理能力极限,水先进入到漏桶里,漏桶里的水按一定速率流出,当流出的速率小于流入的速率时,由于漏桶容量有限,后续进入的水直接溢出(拒绝请求),以此实现限流。springboot + aop + Lua分布式限流的最佳实践令牌桶算法:令牌桶算法的原理也比较简单,我们可以理解成医院的挂号看病,只有拿到号以后才可以进行诊病。系统会维护一个令牌(token)桶,以一个恒定的速度往桶里放入令牌(token),这时如果有请求进来想要被处理,则需要先从桶里获取一个令牌(token),当桶里没有令牌(token)可取时,则该请求将被拒绝服务。令牌桶算法通过控制桶的容量、发放令牌的速率,来达到对请求的限制。springboot + aop + Lua分布式限流的最佳实践Nginx配置高可用性怎么配置?当上游服务器(真实访问服务器),一旦出现故障或者是没有及时相应的话,应该直接轮训到下一台服务器,保证服务器的高可用Nginx配置代码:server { listen 80; server_name www.rumenz.com; location / { ### 指定上游服务器负载均衡服务器 proxy_pass http://backServer; ###nginx与上游服务器(真实访问的服务器)超时时间 后端服务器连接的超时时间_发起握手等候响应超时时间 proxy_connect_timeout 1s; ###nginx发送给上游服务器(真实访问的服务器)超时时间 proxy_send_timeout 1s; ### nginx接受上游服务器(真实访问的服务器)超时时间 proxy_read_timeout 1s; index index.html index.htm; } } Nginx怎么判断别IP不可访问?# 如果访问的ip地址为11115,则返回403 if ($remote_addr = 11115) { return 403; } 在nginx中,如何使用未定义的服务器名称来阻止处理请求?只需将请求删除的服务器就可以定义为:服务器名被保留一个空字符串,他在没有主机头字段的情况下匹配请求,而一个特殊的nginx的非标准代码被返回,从而终止连接。怎么限制浏览器访问?## 不允许谷歌浏览器访问 如果是谷歌浏览器返回500 if ($http_user_agent ~ Chrome) { return 500; } Rewrite全局变量是什么?$remote_addr //获取客户端ip $binary_remote_addr //客户端ip(二进制) $remote_port //客户端port,如:50472 $remote_user //已经经过Auth Basic Module验证的用户名 $host //请求主机头字段,否则为服务器名称,如:blog.sakmon.com $request //用户请求信息,如:GET ?a=1&b=2 HTTP/1.1 $request_filename //当前请求的文件的路径名,由root或alias和URI request组合而成,如:/2013/81.html $status //请求的响应状态码,如:200 $body_bytes_sent // 响应时送出的body字节数数量。即使连接中断,这个数据也是精确的,如:40 $content_length // 等于请求行的“Content_Length”的值 $content_type // 等于请求行的“Content_Type”的值 $http_referer // 引用地址 $http_user_agent // 客户端agent信息,如:Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.76 Safari/537.36 $args //与$query_string相同 等于当中URL的参数(GET),如a=1&b=2 $document_uri //与$uri相同 这个变量指当前的请求URI,不包括任何参数(见$args) 如:/2013/81.html $document_root //针对当前请求的根路径设置值 $hostname //如:centos53.localdomain $http_cookie //客户端cookie信息 $cookie_COOKIE //cookie COOKIE变量的值 $is_args //如果有$args参数,这个变量等于”?”,否则等于”",空值,如? $limit_rate //这个变量可以限制连接速率,0表示不限速 $query_string // 与$args相同 等于当中URL的参数(GET),如a=1&b=2 $request_body // 记录POST过来的数据信息 $request_body_file //客户端请求主体信息的临时文件名 $request_method //客户端请求的动作,通常为GET或POST,如:GET $request_uri //包含请求参数的原始URI,不包含主机名,如:/2013/81.html?a=1&b=2 $scheme //HTTP方法(如http,https),如:http $uri //这个变量指当前的请求URI,不包括任何参数(见$args) 如:/2013/81.html $request_completion //如果请求结束,设置为OK. 当请求未结束或如果该请求不是请求链串的最后一个时,为空(Empty),如:OK $server_protocol //请求使用的协议,通常是HTTP/1.0或HTTP/1.1,如:HTTP/1.1 $server_addr //服务器IP地址,在完成一次系统调用后可以确定这个值 $server_name //服务器名称,如:blog.sakmon.com $server_port //请求到达服务器的端口号,如:80 Nginx 如何实现后端服务的健康检查?方式一,利用 nginx 自带模块 ngx_http_proxy_module 和 ngx_http_upstream_module 对后端节点做健康检查。方式二(推荐),利用nginx_upstream_check_module 模块对后端节点做健康检查。Nginx 如何开启压缩?开启nginx gzip压缩后,网页、css、js等静态资源的大小会大大的减少,从而可以节约大量的带宽,提高传输效率,给用户快的体验。虽然会消耗cpu资源,但是为了给用户更好的体验是值得的。开启的配置如下:将以上配置放到nginx.conf的http{ … }节点中。http { # 开启gzip gzip on; # 启用gzip压缩的最小文件;小于设置值的文件将不会被压缩 gzip_min_length 1k; # gzip 压缩级别 1-10 gzip_comp_level 2; # 进行压缩的文件类型。 gzip_types text/plain application/javascript application/x-javascript text/css application/xml text/javascript application/x-httpd-php image/jpeg image/gif image/png; # 是否在http header中添加Vary: Accept-Encoding,建议开启 gzip_vary on; } 保存并重启nginx,刷新页面(为了避免缓存,请强制刷新)就能看到效果了。以谷歌浏览器为例,通过F12看请求的响应头部:我们可以先来对比下,如果我们没有开启zip压缩之前,我们的对应的文件大小,如下所示:现在我们开启了gzip进行压缩后的文件的大小,可以看到如下所示:gzip压缩前后效果对比:jquery原大小90kb,压缩后只有30kb。gzip虽然好用,但是以下类型的资源不建议启用。 1、图片类型原因:图片如jpg、png本身就会有压缩,所以就算开启gzip后,压缩前和压缩后大小没有多大区别,所以开启了反而会白白的浪费资源。(Tips:可以试试将一张jpg图片压缩为zip,观察大小并没有多大的变化。虽然zip和gzip算法不一样,但是可以看出压缩图片的价值并不大) 2、大文件原因:会消耗大量的cpu资源,且不一定有明显的效果。 ngx_http_upstream_module的作用是什么?ngx_http_upstream_module用于定义可通过fastcgi传递、proxy传递、uwsgi传递、memcached传递和scgi传递指令来引用的服务器组。什么是C10K问题?C10K问题是指无法同时处理大量客户端(10,000)的网络套接字。Nginx是否支持将请求压缩到上游?您可以使用Nginx模块gunzip将请求压缩到上游。gunzip模块是一个过滤器,它可以对不支持gzip编码方法的客户机或服务器使用内容编码:gzip来解压缩响应。如何在Nginx中获得当前的时间?要获得Nginx的当前时间,必须使用SSI模块、和date_local的变量。Proxy_set_header THE-TIME $date_gmt;用Nginx服务器解释-s的目的是什么?用于运行Nginx -s参数的可执行文件。如何在Nginx服务器上添加模块?在编译过程中,必须选择Nginx模块,因为Nginx不支持模块的运行时间选择。生产中如何设置worker进程的数量呢?在有多个cpu的情况下,可以设置多个worker,worker进程的数量可以设置到和cpu的核心数一样多,如果在单个cpu上起多个worker进程,那么操作系统会在多个worker之间进行调度,这种情况会降低系统性能,如果只有一个cpu,那么只启动一个worker进程就可以了。nginx状态码 499:服务端处理时间过长,客户端主动关闭了连接。 502 服务器错误下面是502的一些可能性 (1).FastCGI进程是否已经启动(2).FastCGI worker进程数是否不够(3).FastCGI执行时间过长fastcgi_connect_timeout 300; fastcgi_send_timeout 300; fastcgi_read_timeout 300; (4).FastCGI Buffer不够,nginx和apache一样,有前端缓冲限制,可以调整缓冲参数 fastcgi_buffer_size 32k; fastcgi_buffers 8 32k; (5). Proxy Buffer不够,如果你用了Proxying,调整 proxy_buffer_size 16k; proxy_buffers 4 16k 转载引用出处https://www.toutiao.com/i7074868404070662693/?tt_from=weixin&utm_campaign=client_share&wxshare_count=1×tamp=1647313048&app=news_article&utm_source=weixin&utm_medium=toutiao_android&use_new_style=1&req_id=2022031510572701021004914907E6D22A&share_token=0ff6a301-6b03-4ebe-ae13-2bb074b93cf1&group_id=7074868404070662693
-
-
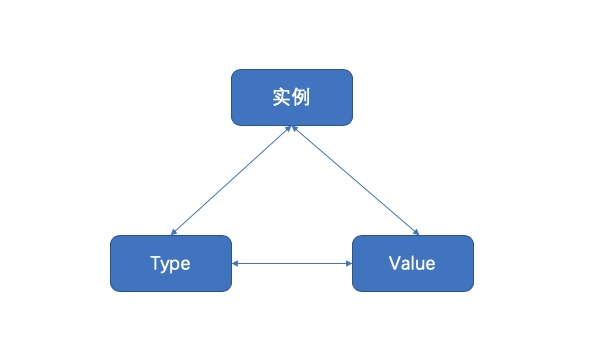
反射reflect 一、引入先看官方Doc中Rob Pike给出的关于反射的定义:Reflection in computing is the ability of a program to examine its own structure, particularly through types; it’s a form of metaprogramming. It’s also a great source of confusion. (在计算机领域,反射是一种让程序——主要是通过类型——理解其自身结构的一种能力。它是元编程的组成之一,同时它也是一大引人困惑的难题。) 维基百科中的定义:在计算机科学中,反射是指计算机程序在运行时(Run time)可以访问、检测和修改它本身状态或行为的一种能力。用比喻来说,反射就是程序在运行的时候能够“观察”并且修改自己的行为。 不同语言的反射模型不尽相同,有些语言还不支持反射。《Go 语言圣经》中是这样定义反射的:Go 语言提供了一种机制在运行时更新变量和检查它们的值、调用它们的方法,但是在编译时并不知道这些变量的具体类型,这称为反射机制。为什么要用反射需要反射的 2 个常见场景: 有时你需要编写一个函数,但是并不知道传给你的参数类型是什么,可能是没约定好;也可能是传入的类型很多,这些类型并不能统一表示。这时反射就会用的上了。 有时候需要根据某些条件决定调用哪个函数,比如根据用户的输入来决定。这时就需要对函数和函数的参数进行反射,在运行期间动态地执行函数。 但是对于反射,还是有几点不太建议使用反射的理由: 与反射相关的代码,经常是难以阅读的。在软件工程中,代码可读性也是一个非常重要的指标。 Go 语言作为一门静态语言,编码过程中,编译器能提前发现一些类型错误,但是对于反射代码是无能为力的。所以包含反射相关的代码,很可能会运行很久,才会出错,这时候经常是直接 panic,可能会造成严重的后果。 反射对性能影响还是比较大的,比正常代码运行速度慢一到两个数量级。所以,对于一个项目中处于运行效率关键位置的代码,尽量避免使用反射特性。 二、相关基础反射是如何实现的?我们以前学习过 interface,它是 Go 语言实现抽象的一个非常强大的工具。当向接口变量赋予一个实体类型的时候,接口会存储实体的类型信息,反射就是通过接口的类型信息实现的,反射建立在类型的基础上。Go 语言在 reflect 包里定义了各种类型,实现了反射的各种函数,通过它们可以在运行时检测类型的信息、改变类型的值。在进行更加详细的了解之前,我们需要重新温习一下Go语言相关的一些特性,所谓温故知新,从这些特性中了解其反射机制是如何使用的。 特点 说明 go语言是静态类型语言。 编译时类型已经确定,比如对已基本数据类型的再定义后的类型,反射时候需要确认返回的是何种类型。 空接口interface{} go的反射机制是要通过接口来进行的,而类似于Java的Object的空接口可以和任何类型进行交互,因此对基本数据类型等的反射也直接利用了这一特点 Go语言的类型: 变量包括(type, value)两部分 理解这一点就知道为什么nil != nil了 type 包括 static type和concrete type. 简单来说 static type是你在编码是看见的类型(如int、string),concrete type是runtime系统看见的类型 类型断言能否成功,取决于变量的concrete type,而不是static type。因此,一个 reader变量如果它的concrete type也实现了write方法的话,它也可以被类型断言为writer。 Go是静态类型语言。每个变量都拥有一个静态类型,这意味着每个变量的类型在编译时都是确定的:int,float32, *AutoType, []byte, chan []int 诸如此类。在反射的概念中, 编译时就知道变量类型的是静态类型;运行时才知道一个变量类型的叫做动态类型。 静态类型静态类型就是变量声明时的赋予的类型。比如: type MyInt int // int 就是静态类型 type A struct{ Name string // string就是静态 } var i *int // *int就是静态类型 动态类型动态类型:运行时给这个变量赋值时,这个值的类型(如果值为nil的时候没有动态类型)。一个变量的动态类型在运行时可能改变,这主要依赖于它的赋值(前提是这个变量是接口类型)。 var A interface{} // 静态类型interface{} A = 10 // 静态类型为interface{} 动态为int A = "String" // 静态类型为interface{} 动态为string var M *int A = M // A的值可以改变 Go语言的反射就是建立在类型之上的,Golang的指定类型的变量的类型是静态的(也就是指定int、string这些的变量,它的type是static type),在创建变量的时候就已经确定,反射主要与Golang的interface类型相关(它的type是concrete type),只有interface类型才有反射一说。在Golang的实现中,每个interface变量都有一个对应pair,pair中记录了实际变量的值和类型:(value, type) value是实际变量值,type是实际变量的类型。一个interface{}类型的变量包含了2个指针,一个指针指向值的类型【对应concrete type】,另外一个指针指向实际的值【对应value】。例如,创建类型为*os.File的变量,然后将其赋给一个接口变量r:tty, err := os.OpenFile("/dev/tty", os.O_RDWR, 0) var r io.Reader r = tty 接口变量r的pair中将记录如下信息:(tty, *os.File),这个pair在接口变量的连续赋值过程中是不变的,将接口变量r赋给另一个接口变量w:var w io.Writer w = r.(io.Writer) 接口变量w的pair与r的pair相同,都是:(tty, *os.File),即使w是空接口类型,pair也是不变的。interface及其pair的存在,是Golang中实现反射的前提,理解了pair,就更容易理解反射。反射就是用来检测存储在接口变量内部(值value;类型concrete type) pair对的一种机制。所以我们要理解两个基本概念 Type 和 Value,它们也是 Go语言包中 reflect 空间里最重要的两个类型。三、Type和Value我们一般用到的包是reflect包。既然反射就是用来检测存储在接口变量内部(值value;类型concrete type) pair对的一种机制。那么在Golang的reflect反射包中有什么样的方式可以让我们直接获取到变量内部的信息呢? 它提供了两种类型(或者说两个方法)让我们可以很容易的访问接口变量内容,分别是reflect.ValueOf() 和 reflect.TypeOf(),看看官方的解释// ValueOf returns a new Value initialized to the concrete value // stored in the interface i. ValueOf(nil) returns the zero func ValueOf(i interface{}) Value {...} 翻译一下:ValueOf用来获取输入参数接口中的数据的值,如果接口为空则返回0 // TypeOf returns the reflection Type that represents the dynamic type of i. // If i is a nil interface value, TypeOf returns nil. func TypeOf(i interface{}) Type {...} 翻译一下:TypeOf用来动态获取输入参数接口中的值的类型,如果接口为空则返回nil reflect.TypeOf()是获取pair中的type,reflect.ValueOf()获取pair中的value。首先需要把它转化成reflect对象(reflect.Type或者reflect.Value,根据不同的情况调用不同的函数。t := reflect.TypeOf(i) //得到类型的元数据,通过t我们能获取类型定义里面的所有元素 v := reflect.ValueOf(i) //得到实际的值,通过v我们获取存储在里面的值,还可以去改变值 示例代码:package main import ( "fmt" "reflect" ) func main() { //反射操作:通过反射,可以获取一个接口类型变量的 类型和数值 var x float64 =3.4 fmt.Println("type:",reflect.TypeOf(x)) //type: float64 fmt.Println("value:",reflect.ValueOf(x)) //value: 3.4 fmt.Println("-------------------") //根据反射的值,来获取对应的类型和数值 v := reflect.ValueOf(x) fmt.Println("kind is float64: ",v.Kind() == reflect.Float64) fmt.Println("type : ",v.Type()) fmt.Println("value : ",v.Float()) } 运行结果:type: float64 value: 3.4 ------------------- kind is float64: true type : float64 value : 3.4 说明 reflect.TypeOf: 直接给到了我们想要的type类型,如float64、int、各种pointer、struct 等等真实的类型 reflect.ValueOf:直接给到了我们想要的具体的值,如1.2345这个具体数值,或者类似&{1 "Allen.Wu" 25} 这样的结构体struct的值 也就是说明反射可以将“接口类型变量”转换为“反射类型对象”,反射类型指的是reflect.Type和reflect.Value这两种 Type 和 Value 都包含了大量的方法,其中第一个有用的方法应该是 Kind,这个方法返回该类型的具体信息:Uint、Float64 等。Value 类型还包含了一系列类型方法,比如 Int(),用于返回对应的值。以下是Kind的种类:// A Kind represents the specific kind of type that a Type represents. // The zero Kind is not a valid kind. type Kind uint const ( Invalid Kind = iota Bool Int Int8 Int16 Int32 Int64 Uint Uint8 Uint16 Uint32 Uint64 Uintptr Float32 Float64 Complex64 Complex128 Array Chan Func Interface Map Ptr Slice String Struct UnsafePointer ) 四、反射的规则其实反射的操作步骤非常的简单,就是通过实体对象获取反射对象(Value、Type),然后操作相应的方法即可。下图描述了实例、Value、Type 三者之间的转换关系:反射 API 的分类总结如下:1) 从实例到 Value通过实例获取 Value 对象,直接使用 reflect.ValueOf() 函数。例如:func ValueOf(i interface {}) Value 2) 从实例到 Type通过实例获取反射对象的 Type,直接使用 reflect.TypeOf() 函数。例如:func TypeOf(i interface{}) Type 3) 从 Type 到 ValueType 里面只有类型信息,所以直接从一个 Type 接口变量里面是无法获得实例的 Value 的,但可以通过该 Type 构建一个新实例的 Value。reflect 包提供了两种方法,示例如下://New 返回的是一个 Value,该 Value 的 type 为 PtrTo(typ),即 Value 的 Type 是指定 typ 的指针类型 func New(typ Type) Value //Zero 返回的是一个 typ 类型的零佳,注意返回的 Value 不能寻址,位不可改变 func Zero(typ Type) Value 如果知道一个类型值的底层存放地址,则还有一个函数是可以依据 type 和该地址值恢复出 Value 的。例如:func NewAt(typ Type, p unsafe.Pointer) Value 4) 从 Value 到 Type从反射对象 Value 到 Type 可以直接调用 Value 的方法,因为 Value 内部存放着到 Type 类型的指针。例如:func (v Value) Type() Type 5) 从 Value 到实例Value 本身就包含类型和值信息,reflect 提供了丰富的方法来实现从 Value 到实例的转换。例如://该方法最通用,用来将 Value 转换为空接口,该空接口内部存放具体类型实例 //可以使用接口类型查询去还原为具体的类型 func (v Value) Interface() (i interface{}) //Value 自身也提供丰富的方法,直接将 Value 转换为简单类型实例,如果类型不匹配,则直接引起 panic func (v Value) Bool () bool func (v Value) Float() float64 func (v Value) Int() int64 func (v Value) Uint() uint64 6) 从 Value 的指针到值从一个指针类型的 Value 获得值类型 Value 有两种方法,示例如下。//如果 v 类型是接口,则 Elem() 返回接口绑定的实例的 Value,如采 v 类型是指针,则返回指针值的 Value,否则引起 panic func (v Value) Elem() Value //如果 v 是指针,则返回指针值的 Value,否则返回 v 自身,该函数不会引起 panic func Indirect(v Value) Value 7) Type 指针和值的相互转换指针类型 Type 到值类型 Type。例如://t 必须是 Array、Chan、Map、Ptr、Slice,否则会引起 panic //Elem 返回的是其内部元素的 Type t.Elem() Type 值类型 Type 到指针类型 Type。例如://PtrTo 返回的是指向 t 的指针型 Type func PtrTo(t Type) Type 8) Value 值的可修改性Value 值的修改涉及如下两个方法://通过 CanSet 判断是否能修改 func (v Value ) CanSet() bool //通过 Set 进行修改 func (v Value ) Set(x Value) Value 值在什么情况下可以修改?我们知道实例对象传递给接口的是一个完全的值拷贝,如果调用反射的方法 reflect.ValueOf() 传进去的是一个值类型变量, 则获得的 Value 实际上是原对象的一个副本,这个 Value 是无论如何也不能被修改的。根据 Go 官方关于反射的博客,反射有三大定律: Reflection goes from interface value to reflection object. Reflection goes from reflection object to interface value. To modify a reflection object, the value must be settable.第一条是最基本的:反射可以从接口值得到反射对象。 反射是一种检测存储在 interface中的类型和值机制。这可以通过 TypeOf函数和 ValueOf函数得到。第二条实际上和第一条是相反的机制,反射可以从反射对象获得接口值。 它将 ValueOf的返回值通过 Interface()函数反向转变成 interface变量。前两条就是说 接口型变量和 反射类型对象可以相互转化,反射类型对象实际上就是指的前面说的 reflect.Type和 reflect.Value。第三条不太好懂:如果需要操作一个反射变量,则其值必须可以修改。 反射变量可设置的本质是它存储了原变量本身,这样对反射变量的操作,就会反映到原变量本身;反之,如果反射变量不能代表原变量,那么操作了反射变量,不会对原变量产生任何影响,这会给使用者带来疑惑。所以第二种情况在语言层面是不被允许的。 五、反射的使用5.1 从relfect.Value中获取接口interface的信息当执行reflect.ValueOf(interface)之后,就得到了一个类型为”relfect.Value”变量,可以通过它本身的Interface()方法获得接口变量的真实内容,然后可以通过类型判断进行转换,转换为原有真实类型。不过,我们可能是已知原有类型,也有可能是未知原有类型,因此,下面分两种情况进行说明。已知原有类型已知类型后转换为其对应的类型的做法如下,直接通过Interface方法然后强制转换,如下:realValue := value.Interface().(已知的类型) 示例代码:package main import ( "fmt" "reflect" ) func main() { var num float64 = 1.2345 pointer := reflect.ValueOf(&num) value := reflect.ValueOf(num) // 可以理解为“强制转换”,但是需要注意的时候,转换的时候,如果转换的类型不完全符合,则直接panic // Golang 对类型要求非常严格,类型一定要完全符合 // 如下两个,一个是*float64,一个是float64,如果弄混,则会panic convertPointer := pointer.Interface().(*float64) convertValue := value.Interface().(float64) fmt.Println(convertPointer) fmt.Println(convertValue) } 运行结果:0xc000098000 1.2345 说明 转换的时候,如果转换的类型不完全符合,则直接panic,类型要求非常严格! 转换的时候,要区分是指针还是指 也就是说反射可以将“反射类型对象”再重新转换为“接口类型变量” 未知原有类型很多情况下,我们可能并不知道其具体类型,那么这个时候,该如何做呢?需要我们进行遍历探测其Filed来得知,示例如下:package main import ( "fmt" "reflect" ) type Person struct { Name string Age int Sex string } func (p Person)Say(msg string) { fmt.Println("hello,",msg) } func (p Person)PrintInfo() { fmt.Printf("姓名:%s,年龄:%d,性别:%s\n",p.Name,p.Age,p.Sex) } func main() { p1 := Person{"王二狗",30,"男"} DoFiledAndMethod(p1) } // 通过接口来获取任意参数 func DoFiledAndMethod(input interface{}) { getType := reflect.TypeOf(input) //先获取input的类型 fmt.Println("get Type is :", getType.Name()) // Person fmt.Println("get Kind is : ", getType.Kind()) // struct getValue := reflect.ValueOf(input) fmt.Println("get all Fields is:", getValue) //{王二狗 30 男} // 获取方法字段 // 1. 先获取interface的reflect.Type,然后通过NumField进行遍历 // 2. 再通过reflect.Type的Field获取其Field // 3. 最后通过Field的Interface()得到对应的value for i := 0; i < getType.NumField(); i++ { field := getType.Field(i) value := getValue.Field(i).Interface() //获取第i个值 fmt.Printf("字段名称:%s, 字段类型:%s, 字段数值:%v \n", field.Name, field.Type, value) } // 通过反射,操作方法 // 1. 先获取interface的reflect.Type,然后通过.NumMethod进行遍历 // 2. 再公国reflect.Type的Method获取其Method for i := 0; i < getType.NumMethod(); i++ { method := getType.Method(i) fmt.Printf("方法名称:%s, 方法类型:%v \n", method.Name, method.Type) } } 运行结果:get Type is : Person get Kind is : struct get all Fields is: {王二狗 30 男} 字段名称:Name, 字段类型:string, 字段数值:王二狗 字段名称:Age, 字段类型:int, 字段数值:30 字段名称:Sex, 字段类型:string, 字段数值:男 方法名称:PrintInfo, 方法类型:func(main.Person) 方法名称:Say, 方法类型:func(main.Person, string) 说明通过运行结果可以得知获取未知类型的interface的具体变量及其类型的步骤为: 先获取interface的reflect.Type,然后通过NumField进行遍历 再通过reflect.Type的Field获取其Field 最后通过Field的Interface()得到对应的value 通过运行结果可以得知获取未知类型的interface的所属方法(函数)的步骤为: 先获取interface的reflect.Type,然后通过NumMethod进行遍历 再分别通过reflect.Type的Method获取对应的真实的方法(函数) 最后对结果取其Name和Type得知具体的方法名 也就是说反射可以将“反射类型对象”再重新转换为“接口类型变量” struct 或者 struct 的嵌套都是一样的判断处理方式 如果是struct的话,可以使用Elem()tag := t.Elem().Field(0).Tag //获取定义在struct里面的Tag属性 name := v.Elem().Field(0).String() //获取存储在第一个字段里面的值 5.2 通过reflect.Value设置实际变量的值reflect.Value是通过reflect.ValueOf(X)获得的,只有当X是指针的时候,才可以通过reflec.Value修改实际变量X的值,即:要修改反射类型的对象就一定要保证其值是“addressable”的。这里需要一个方法:解释起来就是:Elem返回接口v包含的值或指针v指向的值。如果v的类型不是interface或ptr,它会恐慌。如果v为零,则返回零值。package main import ( "fmt" "reflect" ) func main() { var num float64 = 1.2345 fmt.Println("old value of pointer:", num) // 通过reflect.ValueOf获取num中的reflect.Value,注意,参数必须是指针才能修改其值 pointer := reflect.ValueOf(&num) newValue := pointer.Elem() fmt.Println("type of pointer:", newValue.Type()) fmt.Println("settability of pointer:", newValue.CanSet()) // 重新赋值 newValue.SetFloat(77) fmt.Println("new value of pointer:", num) //////////////////// // 如果reflect.ValueOf的参数不是指针,会如何? //pointer = reflect.ValueOf(num) //newValue = pointer.Elem() // 如果非指针,这里直接panic,“panic: reflect: call of reflect.Value.Elem on float64 Value” } 运行结果:old value of pointer: 1.2345 type of pointer: float64 settability of pointer: true new value of pointer: 77 说明 需要传入的参数是* float64这个指针,然后可以通过pointer.Elem()去获取所指向的Value,注意一定要是指针。 如果传入的参数不是指针,而是变量,那么 通过Elem获取原始值对应的对象则直接panic 通过CanSet方法查询是否可以设置返回false newValue.CantSet()表示是否可以重新设置其值,如果输出的是true则可修改,否则不能修改,修改完之后再进行打印发现真的已经修改了。 reflect.Value.Elem() 表示获取原始值对应的反射对象,只有原始对象才能修改,当前反射对象是不能修改的 也就是说如果要修改反射类型对象,其值必须是“addressable”【对应的要传入的是指针,同时要通过Elem方法获取原始值对应的反射对象】 struct 或者 struct 的嵌套都是一样的判断处理方式 5.3 通过reflect.Value来进行方法的调用这算是一个高级用法了,前面我们只说到对类型、变量的几种反射的用法,包括如何获取其值、其类型、以及如何重新设置新值。但是在项目应用中,另外一个常用并且属于高级的用法,就是通过reflect来进行方法【函数】的调用。比如我们要做框架工程的时候,需要可以随意扩展方法,或者说用户可以自定义方法,那么我们通过什么手段来扩展让用户能够自定义呢?关键点在于用户的自定义方法是未可知的,因此我们可以通过reflect来搞定。Call()方法:通过反射,调用方法。先获取结构体对象,然后示例代码:package main import ( "fmt" "reflect" ) type Person struct { Name string Age int Sex string } func (p Person)Say(msg string) { fmt.Println("hello,",msg) } func (p Person)PrintInfo() { fmt.Printf("姓名:%s,年龄:%d,性别:%s\n",p.Name,p.Age,p.Sex) } func (p Person) Test(i,j int,s string){ fmt.Println(i,j,s) } // 如何通过反射来进行方法的调用? // 本来可以用结构体对象.方法名称()直接调用的, // 但是如果要通过反射, // 那么首先要将方法注册,也就是MethodByName,然后通过反射调动mv.Call func main() { p2 := Person{"Ruby",30,"男"} // 1. 要通过反射来调用起对应的方法,必须要先通过reflect.ValueOf(interface)来获取到reflect.Value, // 得到“反射类型对象”后才能做下一步处理 getValue := reflect.ValueOf(p2) // 2.一定要指定参数为正确的方法名 // 先看看没有参数的调用方法 methodValue1 := getValue.MethodByName("PrintInfo") fmt.Printf("Kind : %s, Type : %s\n",methodValue1.Kind(),methodValue1.Type()) methodValue1.Call(nil) //没有参数,直接写nil args1 := make([]reflect.Value, 0) //或者创建一个空的切片也可以 methodValue1.Call(args1) // 有参数的方法调用 methodValue2 := getValue.MethodByName("Say") fmt.Printf("Kind : %s, Type : %s\n",methodValue2.Kind(),methodValue2.Type()) args2 := []reflect.Value{reflect.ValueOf("反射机制")} methodValue2.Call(args2) methodValue3 := getValue.MethodByName("Test") fmt.Printf("Kind : %s, Type : %s\n",methodValue3.Kind(),methodValue3.Type()) args3 := []reflect.Value{reflect.ValueOf(100), reflect.ValueOf(200),reflect.ValueOf("Hello")} methodValue3.Call(args3) } 运行结果:Kind : func, Type : func() 姓名:Ruby,年龄:30,性别:男 姓名:Ruby,年龄:30,性别:男 Kind : func, Type : func(string) hello, 反射机制 Kind : func, Type : func(int, int, string) 100 200 Hello 通过反射,调用函数。首先我们要先确认一点,函数像普通的变量一样,之前的章节中我们在讲到函数的本质的时候,是可以把函数作为一种变量类型的,而且是引用类型。如果说Fun()是一个函数,那么f1 := Fun也是可以的,那么f1也是一个函数,如果直接调用f1(),那么运行的就是Fun()函数。那么我们就先通过ValueOf()来获取函数的反射对象,可以判断它的Kind,是一个func,那么就可以执行Call()进行函数的调用。示例代码:package main import ( "fmt" "reflect" ) func main() { //函数的反射 f1 := fun1 value := reflect.ValueOf(f1) fmt.Printf("Kind : %s , Type : %s\n",value.Kind(),value.Type()) //Kind : func , Type : func() value2 := reflect.ValueOf(fun2) fmt.Printf("Kind : %s , Type : %s\n",value2.Kind(),value2.Type()) //Kind : func , Type : func(int, string) //通过反射调用函数 value.Call(nil) value2.Call([]reflect.Value{reflect.ValueOf(100),reflect.ValueOf("hello")}) } func fun1(){ fmt.Println("我是函数fun1(),无参的。。") } func fun2(i int, s string){ fmt.Println("我是函数fun2(),有参数。。",i,s) } 说明 要通过反射来调用起对应的方法,必须要先通过reflect.ValueOf(interface)来获取到reflect.Value,得到“反射类型对象”后才能做下一步处理 reflect.Value.MethodByName这个MethodByName,需要指定准确真实的方法名字,如果错误将直接panic,MethodByName返回一个函数值对应的reflect.Value方法的名字。 []reflect.Value,这个是最终需要调用的方法的参数,可以没有或者一个或者多个,根据实际参数来定。 reflect.Value的 Call 这个方法,这个方法将最终调用真实的方法,参数务必保持一致,如果reflect.Value.Kind不是一个方法,那么将直接panic。 本来可以用对象访问方法直接调用的,但是如果要通过反射,那么首先要将方法注册,也就是MethodByName,然后通过反射调用methodValue.Call 本文参照:http://www.sohu.com/a/313420275_657921https://studygolang.com/articles/12348?fr=sidebarhttp://c.biancheng.net/golang/源代码:https://github.com/rubyhan1314/go_reflect
-
Prometheus之存储及WAL 一、整体介绍Prometheus 2.x 采用自定义的存储格式将样本数据保存在本地磁盘当中。 如下所示,按照两个小时(最少时间)为一个时间窗口, 将两小时内产生的数据存储在一个块(Block)中, 每一个块中包含该时间窗口内的所有样本数据(chunks), 元数据文件(meta.json)以及索引文件(index) 二、block├── 01E2MA5GDWMP69GVBVY1W5AF1X │ ├── chunks # 保存压缩后的时序数据,每个chunks大小为512M,超过会生成新的chunks │ │ └── 000001 │ ├── index # chunks中的偏移位置 │ ├── meta.json # 记录block块元信息,比如 样本的起始时间、chunks数量和数据量大小等 │ └── tombstones # 通过API方式对数据进行软删除,将删除记录存储在此处(API的删除方式,并不是立即将数据从chunks文件中移除) ├── 01E2MH175FV0JFB7EGCRZCX8NF │ ├── chunks │ │ └── 000001 │ ├── index │ ├── meta.json │ └── tombstones ├── 01E2MQWYDFQAXXPB3M1HK6T20A │ ├── chunks │ │ └── 000001 │ ├── index │ ├── meta.json │ └── tombstones ├── lock ├── queries.active └── wal #防止数据丢失(数据收集上来暂时是存放在内存中,wal记录了这些信息) ├── 00000366 #每个数据段最大为128M,存储默认存储两个小时的数据量。 ├── 00000367 ├── 00000368 ├── 00000369 └── checkpoint.000365 └── 00000000 2.1 解析TSDB将存储的监控数据按照时间分成多个block存储, 默认最小的block保存时间为2h, 后台程序还会将小块合并成大块, 减少内存中block的数量, 便于索引查找数据, 可以通过meta.json查看, 可以看到01E2MA5GDWMP69GVBVY1W5AF1X被压缩1次, source有3个block, 那么2*3=6小时的数据量。 2.2 关于block压缩* 最初的两个小时的块最终会在后台压缩为更长时间的块; * 压缩的最大时间块为数据保留时间的10%或者31天,取两者的较小者。 2.3 head block* head block中的数据是被存储在内存中的并且可以被任意修改; * head block和后续的block初始设定保存2h数据,当head block超过3h时,会被拆分为2h+1h,2h block会变成只读块写入磁盘.(通过观察服务器上prometheus存储目录,每次压缩合并小块时间都比块内部时间多三个小时,为head block) 三、WAL(Write-ahead logging, 预写日志)Prometheus为了防止丢失暂存在内存中的还未被写入磁盘的监控数据,引入了WAL机制。 WAL被分割成默认大小为128M的文件段(segment), 之前版本默认大小是256M, 文件段以数字命名, 长度为8位的整形。 WAL的写入单位是页(page),每页的大小为32KB,所以每个段大小必须是页的大小的整数倍。 如果WAL一次性写入的页数超过一个段的空闲页数,就会创建一个新的文件段来保存这些页,从而确保一次性写入的页不会跨段存储。 3.1 数据流向prometheus将周期性采集到的数据通过Add接口添加到head block, 但是这些数据暂时没有持久化, TSDB通过WAL将数据保存到磁盘上(保存的数据没有压缩,占用内存较大),当出现宕机,启动多协程读取WAL,恢复数据。 四、和存储相关的启动参数–storage.tsdb.path: This determines where Prometheus writes its database. Defaults to data/. –storage.tsdb.retention.time: This determines when to remove old data. Defaults to 15d. Overrides storage.tsdb.retention if this flag is set to anything other than default. –storage.tsdb.retention.size: [EXPERIMENTAL] This determines the maximum number of bytes that storage blocks can use (note that this does not include the WAL size, which can be substantial). The oldest data will be removed first. Defaults to 0 or disabled. This flag is experimental and can be changed in future releases. Units supported: KB, MB, GB, PB. Ex: “512MB” –storage.tsdb.retention: This flag has been deprecated in favour of storage.tsdb.retention.time. –storage.tsdb.wal -compression: This flag enables compression of the write-ahead log (WAL). Depending on your data, you can expect the WAL size to be halved with little extra cpu load. Note that if you enable this flag and subsequently downgrade Prometheus to a version below 2.11.0 you will need to delete your WAL as it will be unreadable. PS: 以上有两个参数storage.tsdb.retention.size和storage.tsdb.retention.time,两个同时设置时,两者无优先级,谁先触发就执行删除操作。 其它启动参数参考promethes#promethes 第五章节启动参数部分)五、总结5.1 需要解决的几个问题1.远程存储节点长时间挂掉(默认blocK大小为2小时, 实际大于六小时,prometheus2.15经测试验证非官方文档说的两个小时), 刷盘到prometheus的数据库中的数据还能不能同步到远程? 5.2 WAL的缓存数据的时间可不可以调整?1.根据远程写参数优化可知,prometheus本地存储和远程存储并无影响。 因为远程存储是通过将WAL中的数据缓存到多个内存队列(shards)中,然后写到远程存储设备,其直接与WAL打交道。 而prometheus只是用WAL来防止数据丢失,其存储的一系列动作都与WAL没关系。 所以当内存中缓存的数据达到刷盘的阈值,WAL中没有写到远程存储的数据就会丢失, 当重新启动远程存储服务,原来那部分没有写入远程存储服务的数据已经丢失, 只能从最新的数据开始写入远程存储 1. 可以调整,准确来说是间接调整。wal保留数据的长短与prometheus最小压缩block大小有关系, 2. 由于wal中至少保留当前时间正在写入的文件之外的三个文件(每个文件保存一个block大小的数据量 3. 所以当增大block大小的时候就会相应的增大wal保存的数据量,但是,block的大小调整会直接影响内存的使用,需要根据现有的环境进行相应的调优。 当我设置–storage.tsdb.min-block-duration=4h(prometheus的启动参数)时,wal中当前保留的文件(存在的数据时间范围:2022.02.20 20:00:00–2022.02.21 13.52),其中每个文件保留4个小时的数据量。
-
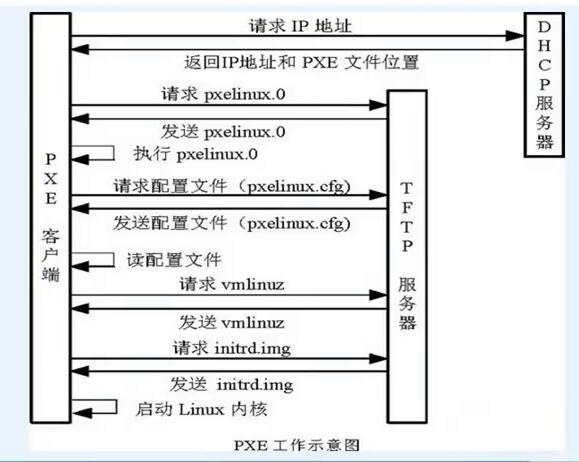
pxe 自动化安装系统 1.需求公司机房需要reinstall os 2.pxe原理2.1 原理与概念事实上把PXE称作是一种引导方式而不是安装方式似乎更加准确, PXE(Pre-boot Execution Environment)是由Intel设计的协议, 它可以使计算机通过网络启动, 但是有一个前提条件是计算机的网卡必须具有引导功能, 这个网卡中要有一个PXE客户端。 当计算机POST自检成功以后,BIOS把网卡中ROM的PXE客户端调入内存执行, PXE客户端通过网络中的DHCP服务器获取一个IP地址, 拿到IP地址以后PXE继续引导计算机与网络中的TFTP客户端建立连接, 从而从TFTP服务器中获取开机引导文件之后请求并下载安装需要的文件。 在这个过程中需要一台服务器来提供启动文件、安装文件、 以及安装过程中的自动应答文件等 2.2 pxe工作流程图原理介绍 Client向PXE Server上的DHCP发送IP地址请求消息,DHCP检测Client是否合法(主要是检测Client的网卡MAC地址),如果合法则返回Client的IP地址,同时将启动文件pxelinux.0的位置信息一并传送给Client Client向PXE Server上的TFTP发送获取pxelinux.0请求消息,TFTP接收到消息之后再向Client发送pxelinux.0大小信息,试探Client是否满意,当TFTP收到Client发回的同意大小信息之后,正式向Client发送pxelinux.0 Client执行接收到的pxelinux.0文件 Client向TFTP Server发送针对本机的配置信息文件(在TFTP服务的pxelinux.cfg目录下,这是系统菜单文件,格式和isolinux.cfg格式一样,功能也是类似),TFTP将配置文件发回Client,继而Client根据配置文件执行后续操作。 Client向TFTP发送Linux内核请求信息,TFTP接收到消息之后将内核文件发送给Client Client向TFTP发送根文件请求信息,TFTP接收到消息之后返回Linux根文件系统 Client启动Linux内核 Client下载安装源文件,读取自动化安装脚本 3 cobbler3.1 cobbler工作流程 client裸机配置了从网络启动后,开机后会广播包请求DHCP服务器 (cobbler server)发送其分配好的一个IP DHCP服务器(cobbler server)收到请求后发送responese,包括其ip地址 client裸机拿到ip后再向cobbler server发送请求OS引导文件的请求 cobbler server告诉裸机OS引导文件的名字和TFTP server的ip和 port client裸机通过上面告知的TFTP server地址通信,下载引导文件 client裸机执行执行该引导文件,确定加载信息,选择要安装的os, 期间会再向cobbler server请求kickstart文件和os image cobbler server发送请求的kickstart和os iamge client裸机加载kickstart文件 client裸机接收os image,安装该os image 3.3 Cobbler集成的服务PXE服务支持 DHCP服务管理 DNS服务管理(可选bind,dnsmasq) 电源管理 Kickstart服务支持 YUM仓库管理 TFTP(PXE启动时需要) Apache(提供kickstart的安装源,并提供定制化的kickstart配置) 3.4 配置目录配置文件目录: /etc/cobbler /etc/cobbler/settings : cobbler 主配置文件 /etc/cobbler/iso/: iso模板配置文件 /etc/cobbler/pxe: pxe模板文件 /etc/cobbler/power: 电源配置文件 /etc/cobbler/user.conf: web服务授权配置文件 /etc/cobbler/users.digest: web访问的用户名密码配置文件 /etc/cobbler/dhcp.template : dhcp服务器的的配置末班 /etc/cobbler/dnsmasq.template : dns服务器的配置模板 /etc/cobbler/tftpd.template : tftp服务的配置模板 /etc/cobbler/modules.conf : 模块的配置文件 数据目录: /var/lib/cobbler/config/: 用于存放distros,system,profiles 等信 息配置文件 /var/lib/cobbler/triggers/: 用于存放用户定义的cobbler命令 /var/lib/cobbler/kickstart/: 默认存放kickstart文件 /var/lib/cobbler/loaders/: 存放各种引导程序 镜像目录 /var/www/cobbler/ks_mirror/: 导入的发行版系统的所有数据 /var/www/cobbler/images/ : 导入发行版的kernel和initrd镜像用于 远程网络启动 /var/www/cobbler/repo_mirror/: yum 仓库存储目录 日志目录: /var/log/cobbler/installing: 客户端安装日志 /var/log/cobbler/cobbler.log : cobbler日志 3.5 命令介绍cobbler commands介绍 cobbler check 核对当前设置是否有问题 cobbler list 列出所有的cobbler元素 cobbler report 列出元素的详细信息 cobbler sync 同步配置到数据目录,更改配置最好都要执行下 cobbler reposync 同步yum仓库 cobbler distro 查看导入的发行版系统信息 cobbler system 查看添加的系统信息 cobbler profile 查看配置信息 3.6 /etc/cobbler/settings中重要的参数设置default_password_crypted: "$1$gEc7ilpP$pg5iSOj/mlxTxEslhRvyp/" manage_dhcp:1 manage_tftpd:1 pxe_just_once:1 next_server:< tftp服务器的 IP 地址> server: 4. cobbler install4.1 系统信息[root@cobbler ~]# getenforce Disabled [root@cobbler ~]# systemctl status firewalld.service ● firewalld.service - firewalld - dynamic firewall daemon Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled; vendor preset: enabled) Active: inactive (dead) Docs: man:firewalld(1) [root@cobbler ~]# cat /etc/redhat-release CentOS Linux release 7.5.1804 (Core) [root@cobbler ~]# ip r default via 10.0.153.1 dev eth0 proto static metric 100 10.0.153.1 dev eth0 proto static scope link metric 100 10.0.153.116 dev eth0 proto kernel scope link src 10.0.153.116 metric 100 192.168.122.0/24 dev virbr0 proto kernel scope link src 192.168.122.1 [root@cobbler ~]# hostname cobbler 4.1.1 ks文件ks.cfg文件组成大致分为3段 命令段 键盘类型,语言,安装方式等系统的配置,有必选项和可选项,如果缺少某项必选项,安装时会中断并提示用户选择此项的选项 软件包段 %packages @groupname:指定安装的包组 package_name:指定安装的包 -package_name:指定不安装的包 在安装过程中默认安装的软件包,安装软件时会自动分析依赖关系。 脚本段(可选) %pre:安装系统前执行的命令或脚本(由于只依赖于启动镜像,支持的命令很少) %post:安装系统后执行的命令或脚本(基本支持所有命令) 关键字 含义 install 告知安装程序,这是一次全新安装,而不是升级upgrade。 url --url=" " 通过FTP或HTTP从远程服务器上的安装树中安装。url --url="http://10.0.153.118/CentOS-7/"url --url ftp://:@/ nfs 从指定的NFS服务器安装。nfs --server=nfsserver.example.com --dir=/tmp/install-tree text|graphical tesxt:使用文本模式安装。 graphical:在图形模式下根据kickstart执行安装,默认该选项 lang 设置在安装过程中使用的语言以及系统的缺省语言。lang en_US.UTF-8 keyboard 设置系统键盘类型。keyboard us zerombr 清除mbr引导信息。 bootloader 系统引导相关配置。bootloader --location=mbr --driveorder=sda --append="crashkernel=auto rhgb quiet"--location=,指定引导记录被写入的位置.有效的值如下:mbr(缺省),partition(在包含内核的分区的第一个扇区安装引导装载程序)或none(不安装引导装载程序)。--driveorder,指定在BIOS引导顺序中居首的驱动器。--append=,指定内核参数.要指定多个参数,使用空格分隔它们。 network 为通过网络的kickstart安装以及所安装的系统配置联网信息。network --bootproto=dhcp --device=eth0 --onboot=yes --noipv6 --hostname=CentOS6--bootproto=[dhcp/bootp/static]中的一种,缺省值是dhcp。bootp和dhcp被认为是相同的。static方法要求在kickstart文件里输入所有的网络信息。network --bootproto=static --ip=10.0.0.100 --netmask=255.255.255.0 --gateway=10.0.0.2 --nameserver=10.0.0.2请注意所有配置信息都必须在一行上指定,不能使用反斜线来换行。--ip=,要安装的机器的IP地址.--gateway=,IP地址格式的默认网关.--netmask=,安装的系统的子网掩码.--hostname=,安装的系统的主机名.--onboot=,是否在引导时启用该设备.--noipv6=,禁用此设备的IPv6.--nameserver=,配置dns解析. timezone 设置系统时区。timezone --utc Asia/Shanghai authconfig 系统认证信息。authconfig --enableshadow --passalgo=sha512设置密码加密方式为sha512 启用shadow文件。 rootpw root密码 clearpart 清空分区。clearpart --all --initlabel--all 从系统中清除所有分区,--initlable 初始化磁盘标签 part 磁盘分区。part /boot --fstype=ext4 --asprimary --size=200 centos7 是--fstype=xfspart swap --size=1024part / --fstype=ext4 --grow --asprimary --size=200--fstype=,为分区设置文件系统类型.有效的类型为ext2,ext3,swap和vfat。--asprimary,强迫把分区分配为主分区,否则提示分区失败。--size=,以MB为单位的分区最小值.在此处指定一个整数值,如500.不要在数字后面加MB。--grow,告诉分区使用所有可用空间(若有),或使用设置的最大值。 firstboot 负责协助配置redhat一些重要的信息。firstboot --disable selinux 关闭selinux。selinux --disabled firewall 关闭防火墙。firewall --disabled logging 设置日志级别。logging --level=info reboot 设定安装完成后重启,此选项必须存在,不然kickstart显示一条消息,并等待用户按任意键后才重新引导,也可以选择halt关机。 4.2 配置yum源curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo curl -o /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo yum makecache fast 4.3 此次使用docker部署常规部署参考 https://www.cnblogs.com/linuxliu/p/7668048.html 4.3.1 构建镜像FROM centos:7.2.1511 MAINTAINER 595265578@qq.com RUN yum -y install epel-release vim net-tools RUN yum -y install httpd tftp cobbler cobbler-web dhcp xinetd syslinux pykickstart bind && yum clean all RUN (cd /lib/systemd/system/sysinit.target.wants/; for i in *; \ do [ $i == systemd-tmpfiles-setup.service ] || rm -f $i; done); \ rm -f /lib/systemd/system/multi-user.target.wants/*;\ rm -f /etc/systemd/system/*.wants/*;\ rm -f /lib/systemd/system/local-fs.target.wants/*; \ rm -f /lib/systemd/system/sockets.target.wants/*udev*; \ rm -f /lib/systemd/system/sockets.target.wants/*initctl*; \ rm -f /lib/systemd/system/basic.target.wants/*;\ rm -f /lib/systemd/system/anaconda.target.wants/*; VOLUME [ "/sys/fs/cgroup" ] RUN systemctl enable cobblerd;systemctl enable httpd;systemctl enable dhcpd RUN sed -i -e 's/\(^.*disable.*=\) yes/\1 no/' /etc/xinetd.d/tftp RUN touch /etc/xinetd.d/rsync EXPOSE 69 EXPOSE 80 EXPOSE 443 EXPOSE 25151 CMD ["/sbin/init"] 4.3.2 builddocker build . -t cobbler:1.0 4.3.3 运行镜像启动容器前我们要先修改配置文件settings和dhcp.template,下文的10.0.153.118为docker宿主机的IP地址。 将容器内部settings dhcp.template文件拷贝至/opt 目录settings文件中需要修改的内容为:server: 192.168.101.100 #cobbler的服务器地址 next_server: 10.0.153.118 #tftp服务器地址 manage_dhcp: 1 #dhcpg管理设置为1,启用dhcp dhcp.template文件中需要修改的内容为: subnet 10.0.153.118 netmask 255.255.255.0 { #修改网段 option routers 10.0.153.1; #指定网关 option domain-name-servers 10.0.153.118; #指定dns option subnet-mask 255.255.255.0; #指定子网掩码 range dynamic-bootp 10.0.153.120 10.0.153.200; #指定地址池 修改完成后保存文件,并使用如下命令启动容器:docker run \ -d \ --privileged \ --net host \ -v /sys/fs/cgroup:/sys/fs/cgroup:ro \ -v /etc/selinux:/etc/selinux \ -v /opt/settings:/etc/cobbler/settings \ -v /opt/dhcp.template:/etc/cobbler/dhcp.template \ -p 69:69 \ -p 80:80 \ -p 443:443 \ -p 25151:25151 \ --name cobbler1.0 cobbler:1.0 4.3.4 打开浏览器,确认cobbler_web可以访问账号和密码 cobbler/cobbler4.3.5 上传镜像vmware挂在iso镜像系统执行命令mount /dev/cdrom /mnt 拷贝镜像到容器内docker cp /mnt cobbler1.0:/opt/iso7 出现如上提示说明上传完成,之后点击Configuration模块的Distros,检查刚刚上传的镜像。4.3.6 ks文件服务器密码123456配置方法 修改settings文件 default_password_crypted[root@cobbler cobbler]# cat settings |grep pass # what install (root) password is set up for those # The simplest way to change the password is to run # openssl passwd -1 default_password_crypted: "$1$random-p$mzxQ/Sx848sXgvfwJCoZM0" # boot menu. Adding a password to the boot menus templates ldap_search_passwd: '' # This setting is also used by the code that supports using Spacewalk/Satellite users/passwords # URL will be passed directly to the kickstarting system, thus bypassing [root@cobbler cobbler]# openssl passwd -1 -salt 'random-phrase-here' '123456' $1$random-p$mzxQ/Sx848sXgvfwJCoZM0 ks文件模版 install url --url=$tree text lang en_US.UTF-8 keyboard us zerombr bootloader --location=mbr --driveorder=sda --append="crashkernel=auto rhgb quiet" #Network information $SNIPPET('network_config') #network --bootproto=dhcp --device=eth0 --onboot=yes --noipv6 --hostname=CentOS7 timezone --utc Asia/Shanghai authconfig --enableshadow --passalgo=sha512 rootpw --iscrypted $default_password_crypted clearpart --all --initlabel part /boot --asprimary --fstype="ext4" --size=200 part / --fstype="ext4" --grow --size=1 firstboot --disable selinux --disabled firewall --disabled logging --level=info reboot %pre $SNIPPET('log_ks_pre') $SNIPPET('kickstart_start') $SNIPPET('pre_install_network_config') # Enable installation monitoring $SNIPPET('pre_anamon') %end %packages @^minimal @compat-libraries @core @debugging @development bash-completion chrony dos2unix kexec-tools lrzsz nmap sysstat telnet tree vim wget net-tools %end %post systemctl disable postfix.service curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo curl -o /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo %end 5 使用koan实现重新安装系统5.1 在客户端安装koan[root@localhost ~]# rpm -ivh http://dl.fedoraproject.org/pub/epel/7/x86_64/e/epel-release-7-10.noarch.rpm 如何不能使用 请参考上面的阿里云源即可 curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo curl -o /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo [root@localhost ~]# yum install koan -y 5.1 查看cobbler上的配置文件1 [root@localhost ~]# koan --server=10.0.153.118 --list=profiles 2 - looking for Cobbler at http://10.0.0.101:80/cobbler_api 3 centos7-x86_64 重新安装客户端系统[root@localhost ~]# koan --replace-self --server=10.0.153.118 --profile=centos7-x86_64 重启系统后会自动重装系统6 通过dhcp 识别mac地址 自动安装需要关闭vmware dhcp服务 新创建的虚拟机为桥接模式cobbler配置[root@cobbler ~]# egrep -v "^#|^$" /etc/cobbler/settings --- allow_duplicate_hostnames: 0 allow_duplicate_ips: 0 allow_duplicate_macs: 0 allow_dynamic_settings: 0 anamon_enabled: 0 authn_pam_service: "login" auth_token_expiration: 3600 build_reporting_enabled: 0 build_reporting_sender: "" build_reporting_email: [ 'root@localhost' ] build_reporting_smtp_server: "localhost" build_reporting_subject: "" build_reporting_ignorelist: [ "" ] cheetah_import_whitelist: - "random" - "re" - "time" createrepo_flags: "-c cache -s sha" default_kickstart: /var/lib/cobbler/kickstarts/default.ks default_name_servers: [] default_ownership: - "admin" default_password_crypted: "$1$random-p$mzxQ/Sx848sXgvfwJCoZM0" default_template_type: "cheetah" default_virt_bridge: xenbr0 default_virt_file_size: 5 default_virt_ram: 512 default_virt_type: xenpv enable_gpxe: 0 enable_menu: 1 func_auto_setup: 0 func_master: overlord.example.org http_port: 80 kernel_options: ksdevice: bootif lang: ' ' text: ~ kernel_options_s390x: RUNKS: 1 ramdisk_size: 40000 root: /dev/ram0 ro: ~ ip: off vnc: ~ ldap_server: "ldap.example.com" ldap_base_dn: "DC=example,DC=com" ldap_port: 389 ldap_tls: 1 ldap_anonymous_bind: 1 ldap_search_bind_dn: '' ldap_search_passwd: '' ldap_search_prefix: 'uid=' ldap_tls_cacertfile: '' ldap_tls_keyfile: '' ldap_tls_certfile: '' mgmt_classes: [] mgmt_parameters: from_cobbler: 1 puppet_auto_setup: 0 sign_puppet_certs_automatically: 0 puppetca_path: "/usr/bin/puppet" remove_old_puppet_certs_automatically: 0 manage_dhcp: 1 manage_dns: 0 bind_chroot_path: "" bind_master: 127.0.0.1 manage_genders: 0 bind_manage_ipmi: 0 manage_tftpd: 1 manage_rsync: 0 manage_forward_zones: [] manage_reverse_zones: [] next_server: 10.0.153.118 power_management_default_type: 'ipmitool' power_template_dir: "/etc/cobbler/power" pxe_just_once: 1 pxe_template_dir: "/etc/cobbler/pxe" consoles: "/var/consoles" redhat_management_type: "off" redhat_management_server: "xmlrpc.rhn.redhat.com" redhat_management_key: "" redhat_management_permissive: 0 register_new_installs: 0 reposync_flags: "-l -n -d" restart_dns: 1 restart_dhcp: 1 run_install_triggers: 1 scm_track_enabled: 0 scm_track_mode: "git" server: 10.0.153.118 client_use_localhost: 0 client_use_https: 0 snippetsdir: /var/lib/cobbler/snippets template_remote_kickstarts: 0 virt_auto_boot: 1 webdir: /var/www/cobbler xmlrpc_port: 25151 yum_post_install_mirror: 1 yum_distro_priority: 1 yumdownloader_flags: "--resolve" serializer_pretty_json: 0 replicate_rsync_options: "-avzH" replicate_repo_rsync_options: "-avzH" always_write_dhcp_entries: 0 proxy_url_ext: "" proxy_url_int: "" [root@cobbler ~]# egrep -v "^#|^$" /etc/cobbler/dhcp.template ddns-update-style interim; allow booting; allow bootp; ignore client-updates; set vendorclass = option vendor-class-identifier; option pxe-system-type code 93 = unsigned integer 16; subnet 10.0.153.0 netmask 255.255.255.0 { option routers 10.0.153.1; option domain-name-servers 10.0.153.118; option subnet-mask 255.255.255.0; range dynamic-bootp 10.0.153.120 10.0.153.200; default-lease-time 21600; max-lease-time 43200; next-server $next_server; class "pxeclients" { match if substring (option vendor-class-identifier, 0, 9) = "PXEClient"; if option pxe-system-type = 00:02 { filename "ia64/elilo.efi"; } else if option pxe-system-type = 00:06 { filename "grub/grub-x86.efi"; } else if option pxe-system-type = 00:07 { filename "grub/grub-x86_64.efi"; } else if option pxe-system-type = 00:09 { filename "grub/grub-x86_64.efi"; } else { filename "pxelinux.0"; } } } ## group could be subnet if your dhcp tags line up with your subnets ## or really any valid dhcpd.conf construct ... if you only use the ## default dhcp tag in cobbler, the group block can be deleted for a ## flat configuration group { #for mac in $dhcp_tags[$dhcp_tag].keys(): #set iface = $dhcp_tags[$dhcp_tag][$mac] host $iface.name { #if $iface.interface_type == "infiniband": option dhcp-client-identifier = $mac; #else hardware ethernet $mac; #end if #if $iface.ip_address: fixed-address $iface.ip_address; #end if #if $iface.hostname: option host-name "$iface.hostname"; #end if #if $iface.netmask: option subnet-mask $iface.netmask; #end if #if $iface.gateway: option routers $iface.gateway; #end if #if $iface.enable_gpxe: if exists user-class and option user-class = "gPXE" { filename "http://$cobbler_server/cblr/svc/op/gpxe/system/$iface.owner"; } else if exists user-class and option user-class = "iPXE" { filename "http://$cobbler_server/cblr/svc/op/gpxe/system/$iface.owner"; } else { filename "undionly.kpxe"; } #else filename "$iface.filename"; #end if ## Cobbler defaults to $next_server, but some users ## may like to use $iface.system.server for proxied setups next-server $next_server; ## next-server $iface.next_server; } #end for } cobbler docker 打开tftp 服务 dhcp服务systemctl start tftp dhcpd配置好mac地址以下仅供参考 常规部署4.3.1 install cobblervim /etc/yum.conf 打开keepcache缓存改为1 yum -y install httpd dhcp tftp python-ctypes cobbler xinetd cobbler-web 4.3.2 start cobblersystemctl start httpd systemctl enable httpd systemctl start cobblerd.service systemctl enable cobblerd.service 4.3.3 cobbler check[root@cobbler ~]# cobbler check The following are potential configuration items that you may want to fix: 1 : The 'server' field in /etc/cobbler/settings must be set to something other than localhost, or kickstarting features will not work. This should be a resolvable hostname or IP for the boot server as reachable by all machines that will use it. 2 : For PXE to be functional, the 'next_server' field in /etc/cobbler/settings must be set to something other than 127.0.0.1, and should match the IP of the boot server on the PXE network. 3 : change 'disable' to 'no' in /etc/xinetd.d/tftp 4 : Some network boot-loaders are missing from /var/lib/cobbler/loaders. If you only want to handle x86/x86_64 netbooting, you may ensure that you have installed a *recent* version of the syslinux package installed and can ignore this message entirely. Files in this directory, should you want to support all architectures, should include pxelinux.0, menu.c32, elilo.efi, and yaboot. 5 : enable and start rsyncd.service with systemctl 6 : debmirror package is not installed, it will be required to manage debian deployments and repositories 7 : The default password used by the sample templates for newly installed machines (default_password_crypted in /etc/cobbler/settings) is still set to 'cobbler' and should be changed, try: "openssl passwd -1 -salt 'random-phrase-here' 'your-password-here'" to generate new one 8 : fencing tools were not found, and are required to use the (optional) power management features. install cman or fence-agents to use them Restart cobblerd and then run 'cobbler sync' to apply changes. 按照提示一个一个的解决问题:sed -i 's/^server: 127.0.0.1/server: 10.0.153.116/' /etc/cobbler/settings # 修改server的ip地址为本机ip sed -i 's/^next_server: 127.0.0.1/next_server: 10.0.153.116/' /etc/cobbler/settings # TFTP Server 的IP地址 service tftp { socket_type = dgram protocol = udp wait = yes user = root server = /usr/sbin/in.tftpd server_args = -s /var/lib/tftpboot disable = no # 修改为no per_source = 11 cps = 100 2 flags = IPv4 } [root@localhost ~]# cobbler get-loaders # 下载缺失的文件 task started: 2017-10-15_113824_get_loaders task started (id=Download Bootloader Content, time=Sun Oct 15 11:38:24 2017) downloading https://cobbler.github.io/loaders/README to /var/lib/cobbler/loaders/README downloading https://cobbler.github.io/loaders/COPYING.elilo to /var/lib/cobbler/loaders/COPYING.elilo downloading https://cobbler.github.io/loaders/COPYING.yaboot to /var/lib/cobbler/loaders/COPYING.yaboot downloading https://cobbler.github.io/loaders/COPYING.syslinux to /var/lib/cobbler/loaders/COPYING.syslinux downloading https://cobbler.github.io/loaders/elilo-3.8-ia64.efi to /var/lib/cobbler/loaders/elilo-ia64.efi downloading https://cobbler.github.io/loaders/yaboot-1.3.17 to /var/lib/cobbler/loaders/yaboot downloading https://cobbler.github.io/loaders/pxelinux.0-3.86 to /var/lib/cobbler/loaders/pxelinux.0 downloading https://cobbler.github.io/loaders/menu.c32-3.86 to /var/lib/cobbler/loaders/menu.c32 downloading https://cobbler.github.io/loaders/grub-0.97-x86.efi to /var/lib/cobbler/loaders/grub-x86.efi downloading https://cobbler.github.io/loaders/grub-0.97-x86_64.efi to /var/lib/cobbler/loaders/grub-x86_64.efi *** TASK COMPLETE *** 添加rsync到自启动并启动rsync systemctl enable rsyncd systemctl start rsyncd 修改密码为123456 ,salt后面是常用的加盐方式加密 [root@cobbler ~]# openssl passwd -1 -salt '123456' '123456' $1$123456$wOSEtcyiP2N/IfIl15W6Z0 vim /etc/cobbler/settings # 修改settings配置文件中下面位置,把新生成的密码加进去 default_password_crypted: "$1$123456$wOSEtcyiP2N/IfIl15W6Z0 再次执行cobbler check[root@cobbler ~]# cobbler check The following are potential configuration items that you may want to fix: 1 : Some network boot-loaders are missing from /var/lib/cobbler/loaders. If you only want to handle x86/x86_64 netbooting, you may ensure that you have installed a *recent* version of the syslinux package installed and can ignore this message entirely. Files in this directory, should you want to support all architectures, should include pxelinux.0, menu.c32, elilo.efi, and yaboot. 2 : debmirror package is not installed, it will be required to manage debian deployments and repositories 3 : fencing tools were not found, and are required to use the (optional) power management features. install cman or fence-agents to use them Restart cobblerd and then run 'cobbler sync' to apply changes. ks#platform=x86, AMD64, or Intel EM64T #version=DEVEL # Install OS instead of upgrade install # Keyboard layouts keyboard 'us' # Root password rootpw --iscrypted $1$m1pE0DG6$vALBphGGynqvUzfJaWZ6U1 # Use network installation url --url="$tree" # System language lang en_US # Firewall configuration firewall --disabled # System authorization information auth --useshadow --passalgo=sha512 # Use graphical install graphical firstboot --disable # SELinux configuration selinux --disabled # Network information network --bootproto=dhcp --device=eth0 network --bootproto=dhcp --device=eth1 # Reboot after installation reboot # System timezone timezone Asia/Shanghai # System bootloader configuration bootloader --location=mbr # Clear the Master Boot Record zerombr # Partition clearing information clearpart --all --initlabel # Disk partitioning information part /boot --asprimary --fstype="ext4" --size=200 part / --fstype="ext4" --grow --size=1 %packages @base @core @compat-libraries @debugging @development @gnome-desktop @X Window System %end
-
10 个Linux Awk文本处理经典案例 awk是Linux系统下一个处理文本的编程语言工具,能用简短的程序处理标准输入或文件、数据排序、计算以及生成报表等等,应用非常广泛。 基本的命令语法:awk option 'pattern {action}' file 其中pattern表示awk在数据中查找的内容,而action是在找到匹配内容时所执行的一系列命令。花括号用于根据特定的模式对一系列指令进行分组。 awk处理的工作方式与数据库类似,支持对记录和字段处理,这也是grep和sed不能实现的。 在awk中,缺省的情况下将文本文件中的一行视为一个记录,逐行放到内存中处理,而将一行中的某一部分作为记录中的一个字段。用1,2,3...数字的方式顺序的表示行(记录)中的不同字段。用$后跟数字,引用对应的字段,以逗号分隔,0表示整个行。 下面根据工作经验总结了10个实用的awk案例,面试笔试题也经常会出,供朋友们参考学习 1、分析访问日志(Nginx为例)日志格式: '$remote_addr - $remote_user [$time_local] "$request" $status $body_bytes_sent "$http_referer" "$http_user_agent" "$http_x_forwarded_for"' 1.1统计访问IP次数: # awk '{a[$1]++}END{for(v in a)print v,a[v]}' access.log 统计访问访问大于100次的IP: # awk '{a[$1]++}END{for(v ina){if(a[v]>100)print v,a[v]}}' access.log 统计访问IP次数并排序取前10: # awk '{a[$1]++}END{for(v in a)print v,a[v]|"sort -k2 -nr |head -10"}' access.log 统计时间段访问最多的IP: # awk'$4>="[02/Jan/2017:00:02:00" &&$4<="[02/Jan/2017:00:03:00"{a[$1]++}END{for(v in a)print v,a[v]}'access.log 统计上一分钟访问量: # date=$(date -d '-1 minute'+%d/%d/%Y:%H:%M) # awk -vdate=$date '$4~date{c++}END{printc}' access.log 统计访问最多的10个页面: # awk '{a[$7]++}END{for(vin a)print v,a[v]|"sort -k1 -nr|head -n10"}' access.log 统计每个URL数量和返回内容总大小: # awk '{a[$7]++;size[$7]+=$10}END{for(v ina)print a[v],v,size[v]}' access.log 统计每个IP访问状态码数量: # awk '{a[$1" "$9]++}END{for(v ina)print v,a[v]}' access.log 统计访问IP是404状态次数: # awk '{if($9~/404/)a[$1" "$9]++}END{for(i in a)print v,a[v]}' access.log 2、两个文件差异对比文件内容: # seq 1 5 > a # seq 3 7 > b 找出b文件在a文件相同记录 2.1方法1# awk 'FNR==NR{a[$0];next}{if($0 in a)print $0}' a b 3 4 5 # awk 'FNR==NR{a[$0];next}{if($0 in a)print FILENAME,$0}' a b b 3 b 4 b 5 # awk 'FNR==NR{a[$0]}NR>FNR{if($0 ina)print $0}' a b 3 4 5 # awk 'FNR==NR{a[$0]=1;next}(a[$0]==1)' a b # a[$0]是通过b文件每行获取值,如果是1说明有 # awk 'FNR==NR{a[$0]=1;next}{if(a[$0]==1)print}' a b 3 4 5 2.2 方法2# awk 'FILENAME=="a"{a[$0]}FILENAME=="b"{if($0 in a)print $0}' a b 3 4 5 2.3方法3# awk 'ARGIND==1{a[$0]=1}ARGIND==2 && a[$0]==1' a b 3 4 5 3.找出b文件在a文件不同记录3.1方法1# awk 'FNR==NR{a[$0];next}!($0 in a)' a b 6 7 # awk 'FNR==NR{a[$0]=1;next}(a[$0]!=1)' a b # awk'FNR==NR{a[$0]=1;next}{if(a[$0]!=1)print}' a b 6 7 3.2 方法2# awk'FILENAME=="a"{a[$0]=1}FILENAME=="b" && a[$0]!=1' a b 3.3 方法3# awk 'ARGIND==1{a[$0]=1}ARGIND==2 && a[$0]!=1' a b 4、合并两个文件文件内容: # cat a zhangsan 20 lisi 23 wangwu 29 # cat b zhangsan man lisi woman wangwu man 将a文件合并到b文件 4.1 方法1:# awk 'FNR==NR{a[$1]=$0;next}{print a[$1],$2}' a b zhangsan 20 man lisi 23 woman wangwu 29 man 4.2 方法2# awk 'FNR==NR{a[$1]=$0}NR>FNR{print a[$1],$2}' a b zhangsan 20 man lisi 23 woman wangwu 29 man 将a文件相同IP的服务名合并: # cat a 192.168.1.1: httpd 192.168.1.1: tomcat 192.168.1.2: httpd 192.168.1.2: postfix 192.168.1.3: mysqld 192.168.1.4: httpd # awk 'BEGIN{FS=":";OFS=":"}{a[$1]=a[$1] $2}END{for(v in a)print v,a[v]}' a 192.168.1.4: httpd 192.168.1.1: httpd tomcat 192.168.1.2: httpd postfix 192.168.1.3: mysqld 解读: 数组a存储是$1=a[$1] $2,第一个a[$1]是以第一个字段为下标,值是a[$1] $2,也就是$1=a[$1] $2,值的a[$1]是用第一个字段为下标获取对应的值,但第一次数组a还没有元素,那么a[$1]是空值,此时数组存储是192.168.1.1=httpd,再遇到192.168.1.1时,a[$1]通过第一字段下标获得上次数组的httpd,把当前处理的行第二个字段放到上一次同下标的值后面,作为下标192.168.1.1的新值。此时数组存储是192.168.1.1=httpd tomcat。每次遇到相同的下标(第一个字段)就会获取上次这个下标对应的值与当前字段并作为此下标的新值 5、将第一列合并到一行# cat file 1 2 3 4 5 6 7 8 9 # awk '{for(i=1;i<=NF;i++)a[i]=a[i]$i" "}END{for(vin a)print a[v]}' file 1 4 7 2 5 8 3 6 9 解读: for循环是遍历每行的字段,NF等于3,循环3次。 读取第一行时: 第一个字段:a[1]=a[1]1" " 值a[1]还未定义数组,下标也获取不到对应的值,所以为空,因此a[1]=1 。 第二个字段:a[2]=a[2]2" " 值a[2]数组a已经定义,但没有2这个下标,也获取不到对应的值,为空,因此a[2]=2 。 第三个字段:a[3]=a[3]3" " 值a[2]与上面一样,为空,a[3]=3 。 读取第二行时: 第一个字段:a[1]=a[1]4" " 值a[2]获取数组a的2为下标对应的值,上面已经有这个下标了,对应的值是1,因此a[1]=1 4 第二个字段:a[2]=a[2]5" " 同上,a[2]=2 5 第三个字段:a[3]=a[3]6" " 同上,a[2]=3 6 读取第三行时处理方式同上,数组最后还是三个下标,分别是1=1 4 7,2=2 5 8,3=36 9。最后for循环输出所有下标值。 6、字符串拆分字符串拆分 6.1 方法1# echo "hello" |awk -F '''{for(i=1;i<=NF;i++)print $i}' h e l l o 6.2 方法2# echo "hello" |awk '{split($0,a,"''");for(v in a)print a[v]}' l o h e l 7、统计出现的次数统计字符串中每个字母出现的次数: # echo "a.b.c,c.d.e" |awk -F'[.,]' '{for(i=1;i<=NF;i++)a[$i]++}END{for(v in a)print v,a[v]}' a 1 b 1 c 2 d 1 e 1 8、费用统计得出每个员工出差总费用及次数: # cat a zhangsan 8000 1 zhangsan 5000 1 lisi 1000 1 lisi 2000 1 wangwu 1500 1 zhaoliu 6000 1 zhaoliu 2000 1 zhaoliu 3000 1 # awk '{name[$1]++;cost[$1]+=$2;number[$1]+=$3}END{for(v in name)print v,cost[v],number[v]}' a zhangsan 5000 1 lisi 3000 2 wangwu 1500 1 zhaoliu 11000 3 9、获取某列数字最大数# cat a a b 1 c d 2 e f 3 g h 3 i j 2 获取第三字段最大值: # awk 'BEGIN{max=0}{if($3>max)max=$3}END{print max}' a 3 打印第三字段最大行: # awk 'BEGIN{max=0}{a[$0]=$3;if($3>max)max=$3}END{for(v in a)if(a[v]==max)print v}'a g h 3 e f 3 10、去除文本第一行和最后一行# seq 5 |awk'NR>2{print s}{s=$0}' 2 3 4 解读: 读取第一行,NR=1,不执行print s,s=1 读取第二行,NR=2,不执行print s,s=2 (大于为真) 读取第三行,NR=3,执行print s,此时s是上一次p赋值内容2,s=3 最后一行,执行print s,打印倒数第二行,s=最后一行 11、获取Nginx upstream块内后端IP和端口# cat a upstream example-servers1 { server 127.0.0.1:80 weight=1 max_fails=2fail_timeout=30s; } upstream example-servers2 { server 127.0.0.1:80 weight=1 max_fails=2fail_timeout=30s; server 127.0.0.1:82 backup; } # awk '/example-servers1/,/}/{if(NR>2){print s}{s=$2}}' a 127.0.0.1:80 # awk '/example-servers1/,/}/{if(i>1)print s;s=$2;i++}' a # awk '/example-servers1/,/}/{if(i>1){print s}{s=$2;i++}}' a 127.0.0.1:80 解读: 读取第一行,i初始值为0,0>1为假,不执行print s,x=example-servers1,i=1 读取第二行,i=1,1>1为假,不执行prints,s=127.0.0.1:80,i=2 读取第三行,i=2,2>1为真,执行prints,此时s是上一次s赋值内容127.0.0.1:80,i=3 最后一行,执行print s,打印倒数第二行,s=最后一行。 这种方式与上面一样,只是用i++作为计数器